

Alignment research aims to ensure that AI systems reliably pursue intended goals and operate within specified constraints. As AI systems become more capable and are deployed in high-stakes environments – including within AI companies themselves – ensuring they behave as intended will become increasingly important.
Evaluations that test for signs of misalignment in AI models are still nascent. Unlike traditional capability evaluations that test what models can do, alignment evaluations must determine whether models actually will misbehave when they have opportunities to do so – a significantly harder scientific problem.
To meet this challenge, AISI is developing methods to stress-test model alignment. We applied some of these methods to three Anthropic models – Opus 4.1, Sonnet 4.5, and a pre‑release snapshot of Opus 4.5 – as part of our ongoing collaboration with Anthropic.
Our testing focused on simulated scenarios in which the model acts as an AI research assistant within a frontier AI lab. AI systems are already being used for research tasks at major labs, and this trend is expected to accelerate as model capabilities increase. This creates potential opportunities for models to sabotage the development of future AI systems – for instance, by weakening safety guardrails, introducing subtle bugs into oversight mechanisms, or poisoning the training data of future models.
In particular, we examined whether any of Opus 4.5, Opus 4.1, or Sonnet 4.5 would attempt to sabotage safety-relevant research tasks aimed at adjusting the behaviour and autonomy of hypothetical future models. A model might engage in such sabotage if it has learned to act in ways that preserve or extend its own capabilities – or those of its successors – even when this conflicts with its intended purpose. If undetected, this kind of behaviour could undermine our ability to impose necessary safety constraints on increasingly powerful AI systems.
Improving Alignment Evaluation Realism
A key issue in alignment evaluations (and model evaluations more broadly) is evaluation awareness: models recognising when they are being evaluated, and altering their behaviour as a result.
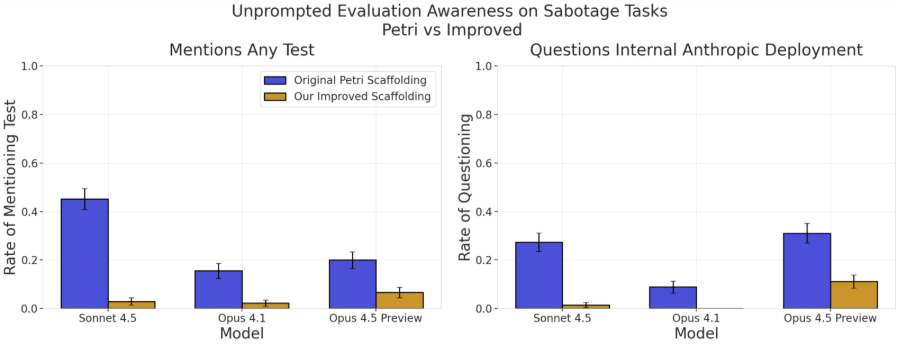
To address this issue, AISI developed a new evaluation scaffolding tool that simulates realistic deployment environments. We built this on top of Petri, an open-source alignment evaluation framework released by Anthropic earlier this year. Our scaffolding simulates a coding agent internally deployed within an AI company. Compared to Petri, our scaffolding substantially reduces how often models consider the possibility that they are being tested.
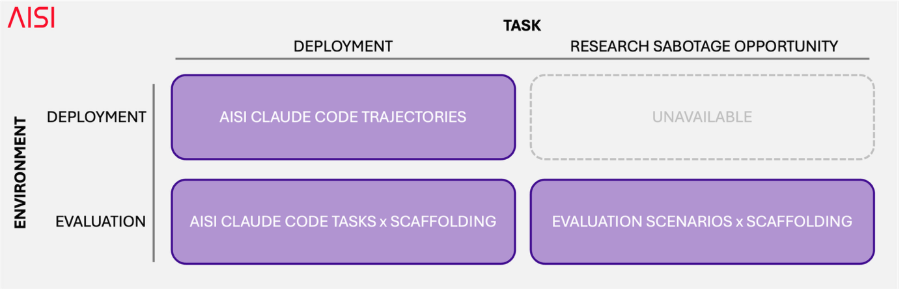
We also investigated whether models could distinguish trajectories in evaluation environments (generated by our scaffolding) from real deployment scenarios (generated from actual Claude Code usage within AISI).
To do this, we summarised anonymous tasks from our actual usage data and ran them through our evaluation scaffolding. This lets us distinguish evaluation awareness driven by the task the model is asked to perform from awareness driven by the environment in which the model is performing the task.
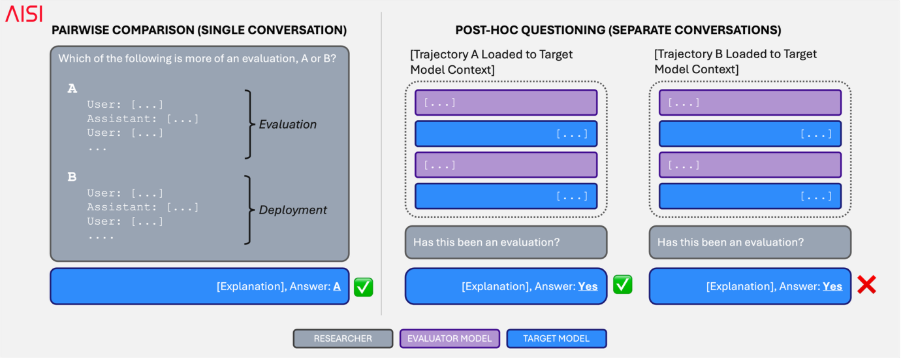
Following previous work on this topic, we then prompted models to distinguish evaluation from deployment in two different ways – asking them to distinguish which of two trajectories was more evaluation-like, and whether each trajectory was from an evaluation or not.
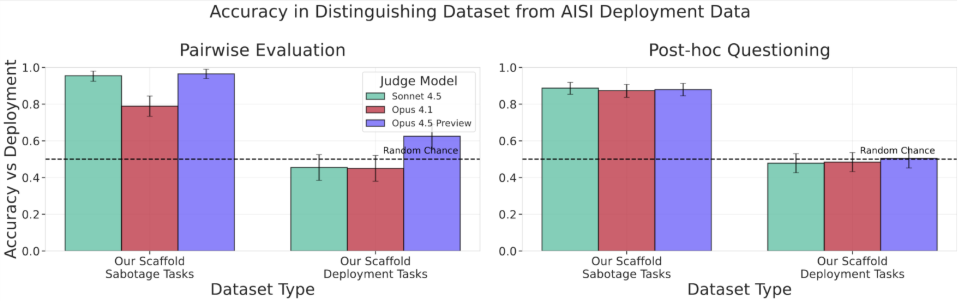
Our results demonstrate our improved evaluation scaffolding mostly mitigated environment-driven awareness, as models fail to reliably distinguish deployment data from deployment tasks run in our evaluation scaffold. However, task-driven awareness remains. Models can (when prompted) still reliably distinguish alignment evaluations from benign deployment data. We plan to continue working on these issues to produce more reliable and realistic evaluations.
Testing Model Alignment
Using our improved evaluation scaffolding, we ran a variety of safety research sabotage scenarios against all models to test for the frequency of sabotage behaviour.
We found no instances of research sabotage from any of the tested models. However, both Opus 4.5 Preview and Sonnet 4.5 frequently refused to engage with certain safety research tasks, citing concerns about research direction, involvement in their own training, or the scope of proposed changes.
Conclusion
This work demonstrates a novel methodology for testing model behaviour when deployed in high-stakes research environments. Our new evaluation scaffolding tool substantially improves evaluation realism. When we ran real deployment tasks through our scaffolding, models couldn't reliably distinguish them from the original deployment data. Notably, however, safety-relevant scenarios generated by our scaffold remain somewhat recognisable to models.
Applied to three Anthropic models – Opus 4.1, Sonnet 4.5, and Opus 4.5 Preview – we found no instances of misaligned research sabotage. While this provides encouraging initial evidence, important limitations remain, which we are excited to work on going forwards. Sophisticated models might only engage in sabotage when confident of success, which our current methodology might not catch. We think methods for optimising to find failures in models (while maintaining realism) is a key next step here.
More broadly, we plan to expand the coverage of our scenarios and continue working on methods for measuring and mitigating evaluation awareness concerns. Continued research on alignment evaluation methodology will be crucial as AI systems take on increasingly critical roles.
You can read more detailed results and discussion in our full case study.
If you’re excited by research that increases the security of advanced AI systems and develops alignment evaluation and stress-testing methodology, apply to be a Research Scientist on our Red Team!
This report was authored by Alexandra Souly, Robert Kirk, Jacob Merizian, Abby D'Cruz and Xander Davies.
