

AI systems can generate vast amounts of outputs as they use tools or respond to queries across multiple turns. These outputs hold important information but making sense of them can be challenging.
Transcript analysis (also called log analysis) plays an important role in our understanding of an AI system’s capabilities and behaviours, as well as the environment in which it operates. For example, transcripts can help us understand not just how often an agent fails or succeeds during an evaluation but why – by revealing failure modes that may not actually reflect its true capabilities, like bugs or refusals. It can also provide insight into a model’s safety-relevant properties, such as whether it misreports progress or omits important information.
To help others in the AI safety and security communities review their own transcripts, we worked closely with Meridian Labs to build Inspect Scout, an open-source transcript analysis tool. Our new paper details seven simple steps for conducting rigorous transcript analysis using Inspect Scout.
In this blog, we explain how Inspect Scout works, and provide a brief overview of our suggested transcript analysis pipeline.
What is Inspect Scout?
Inspect Scout is a tool for conducting systematic, quantitative transcript analysis. It is built on top of our popular evaluation platform, Inspect, and can be scaled to analyse thousands of transcripts in parallel.
It lets you analyse transcripts using scanners, which are functions that take a specific input from a transcript and translate it into a legible result. Scout supports creating your own custom scanners, as well as providing several pre-configured ones. Here are some examples of scanners currently available in Inspect Scout:
- Refusal scanners detect instances of models refusing to complete tasks in compliance with their safety specifications, rather than because they are unable to.
- Evaluation awareness scanners search for evidence that a model is aware it is being evaluated, which may lead it to behave in ways that undermine the eval, such as by sandbagging.
- Command error scanners detect instances of models attempting call tools that are unavailable. This might prompt you to make flagged tools available in your evaluation environment to elicit the model’s full capabilities.
A pipeline for transcript analysis
Our paper sets out a seven-step process for transcript analysis, which aggregates common best practices from across the AI research ecosystem.
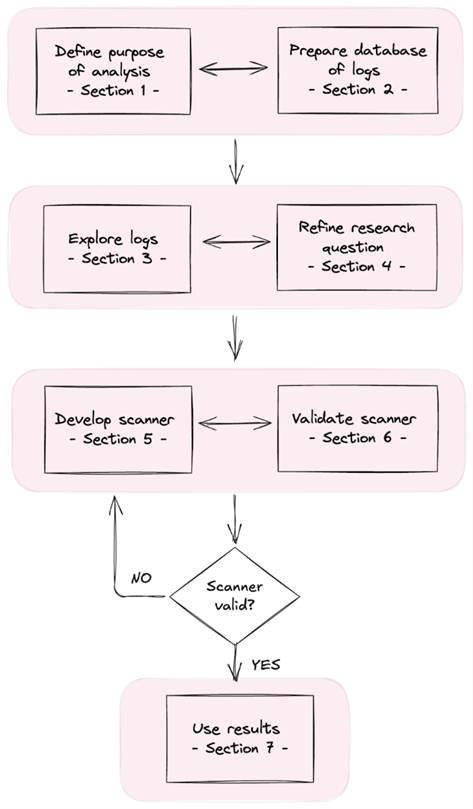
Below we give an overview of each step.
Stage 1: Define the purpose of your analysis
As with any data analysis, the first step is to establish what broad question you are trying to answer. This could be a primary question (“Can this AI agent solve a particular coding challenge?”) or a secondary one (“Can I trust the results of this evaluation?”).
Stage 2: Organise your transcripts
The data you are planning to analyse should be collated in a structured database. You may also want to filter or pre-process data at this stage, such as by removing personal data or imputing any missing values.
Stage 3: Inspect your transcripts
It’s important to manually inspect at least a few samples of your data to get a sense for the structure and content of the transcripts, and to familiarise yourself with how they are formatted. In choosing samples to read, you can filter by several factors, such as length of transcript or whether the agent passed or failed the task.
LLMs can also be used to partially automate this process – either at the transcript level (by querying the LLM about what occurred during a particular task), or at the database level (by searching for statistical patterns or correlations that aren’t apparent from reading individual transcripts).
Stage 4: Refine your research question
Here, you’ll refine the research question defined in stage one. Research questions will need to identify concrete signals which can be located within transcripts. These signals will be operationalised as scanners in the next stage. For example:

Stage 5: Design your scanner
Once you know what signals you’re trying to detect, the next stage is to design a scanner which will perform this function. This involves first deciding at what level you will perform your analysis – for example, you might isolate a particular content type to focus on, like user messages, reasoning traces or tool calls.
Stage 6: Validate your scanner
After running your scanner for the first time, you’ll need to select a subset of the results for validation against a ground truth, to make sure the scanner is working as intended.
Sometimes, this will be objective (“Did the agent generate valid code”?) and therefore easily checkable by a single human annotator. Or it could be subjective (“Was this output harmful”?), in which case you may need multiple annotators to account for disagreements or biases.
Stage 7: Use your results
Broadly, the data you collect from transcript analysis could be useful for two purposes:
- Flagging immediate issues: In some cases, findings will be directly actionable without performing statistical analysis. For example, identifying many refusals could motivate further elicitation attempts, or tool access issues might prompt you to adjust the evaluation environment.
- Further research: The process of running scanners transforms unstructured transcripts into structured data. You can now use this data for downstream analysis to draw conclusions about model behaviour and capabilities, or to forecast future behaviour.
In our paper, we provide detailed implementation guidance for each of the steps described above. This is a first step towards creating a streamlined framework for transcript analysis, but open questions remain! In the final section of the paper, we list some of these questions. We hope to inspire others in the AI safety and security community to investigate them more systematically.
To get started with Inspect Scout, you can also read our full documentation.
