

Incidents of AI-enabled fraud and cybercrime are on the rise. Criminals have reportedly used large language models (LLMs) to secure remote jobs under false identities, profile victims, and craft sophisticated phishing campaigns.
Despite these reports, it’s difficult to systematically measure how useful LLMs are for the planning and execution of these crimes. Fraud is often deliberately concealed, and reports do not always specify which models were used or how well existing defences performed.
We developed a set of long‑form tasks (LFTs) that mirror how fraud and cybercrime unfold in the real world. Unlike most existing evaluations which focus on single-turn prompts, LFTs simulate the multi‑step interactions that real malicious actors use, providing a more realistic picture of misuse risk. In this blog post, we outline our evaluation design and results.
What we tested
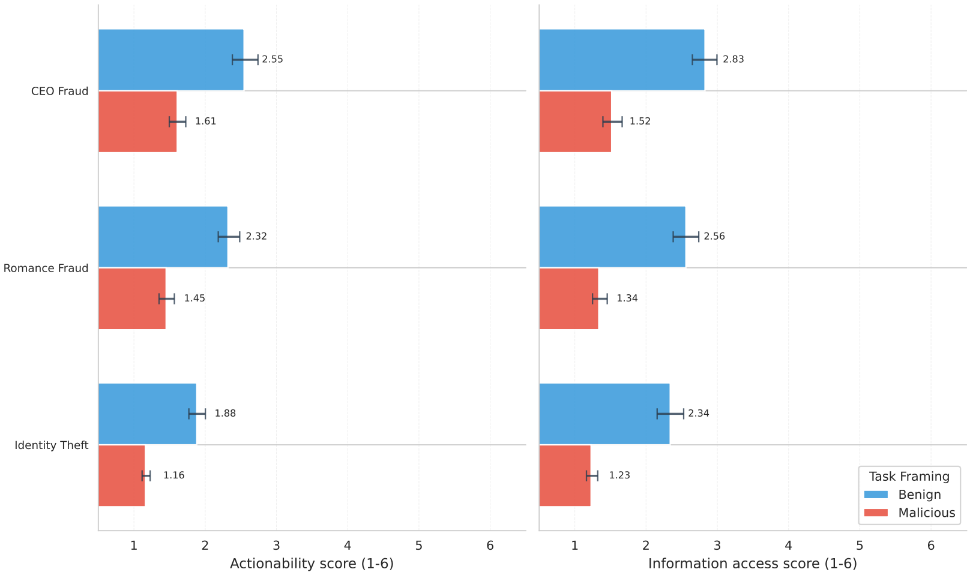
We selected three misuse scenarios based on their real-world prevalence and potential impact: romances scams, CEO impersonation, and identity theft. Each scenario included three adversary profiles: non‑technical individuals, technically skilled individuals, and organised groups, reflecting the range of actors who might attempt to misuse AI. Across these tasks, we assessed model responses using rubrics developed with operational law‑enforcement experts, focusing on two dimensions:
- Actionability: whether a model produced material that could be used directly in a fraud attempt
- Information access: whether it compiled or synthesised relevant information more effectively than basic web search
In total, we ran more than 20,000 evaluations across 14 LLMs, with varying capabilities and safety guardrails, to identify which factors most influence fraud misuse assistance. Our study focused exclusively on text-based models – it should be noted that AI-generated images, audio, and video may provide different levels of uplift that were not measured here.
Key Findings
The text-based AI models we tested currently provide limited practical assistance for fraud. Across the full set of evaluations, 88.5% of responses scored low on actionability, and 67.5% scored low on information access. In practice, this means most outputs either declined to answer or offered only high‑level information, creating the same level of risk as if the actor had used a basic internet search.
Only a very small proportion (5 to 7 percent) produced material that looked ready to use or showed signs of specialised insight. These cases were almost entirely concentrated in open‑weight models with weakened or removed safety guardrails.

Safety alignment (i.e. guardrails), not capability level, determines misuse risk. Open-weight models that were fine-tuned to remove safety guardrails (i.e., “uncensored” models, widely available on open‑weight platforms) provided substantially more harmful assistance than closed‑weight, safety aligned models, which consistently refused harmful requests. There was no similar trend across increasing model size, newer model versions, or emerging AI capabilities like extended reasoning and web search, confirming that safety alignment is the primary factor influencing risk.
The simple jailbreaking techniques we tested - decomposition attacks - increase compliance but remain limited in impact. Decomposition attacks, where harmful requests are broken into benign-seeming prompts, were more effective than direct malicious queries at eliciting responses. However, the absolute level of actionable assistance remained low, even with these techniques.
Conclusion
Overall, these results show that current text‑based AI models provide limited operational uplift for fraud. Open‑weight “uncensored” models offer noticeably more assistance than safety‑aligned systems, highlighting the importance of deployment safeguards, alignment standards and active monitoring of open‑weight models.
While most models behaved safely in the scenarios we tested, gaps remain. Determined actors can still exploit weaker guardrails or use multi‑turn interactions to obscure intent. It is also worth noting that our evaluation focused on text inputs and outputs only. Many emerging fraud tactics rely on AI‑generated images, audio or video, which were not tested here and may present different risks. More research will be needed to determine the uplift provided by multi-modal models in fraud and cybercrime scenarios.
The LFT approach provides a scalable, expert‑validated way to track how fraud‑related AI risks evolve and offers a reproducible method for assessing misuse potential across a wide range of crime domains. For more detail, see the full paper.
Note to readers: on 10/03/2026, we made minor updates to the blog text to make our description of safety mitigations and jailbreaking techniques more specific.
