

Sandboxes are a critical part of AI agent evaluation. They are isolation environments that limit model’s access to external systems and data, allowing evaluators to observe their behaviour and capabilities while avoiding real-world harm. Last year, we released our Inspect Sandboxing Toolkit, a series of plugins purpose-built for safely evaluating AI agents.
But as agents grow more advanced, there is a risk that they could find and exploit vulnerabilities in these sandboxes, undermining their security. We’ve developed SandboxEscapeBench, an open-source benchmark dedicated to evaluating whether AI agents can break out of their sandboxes.
What we built
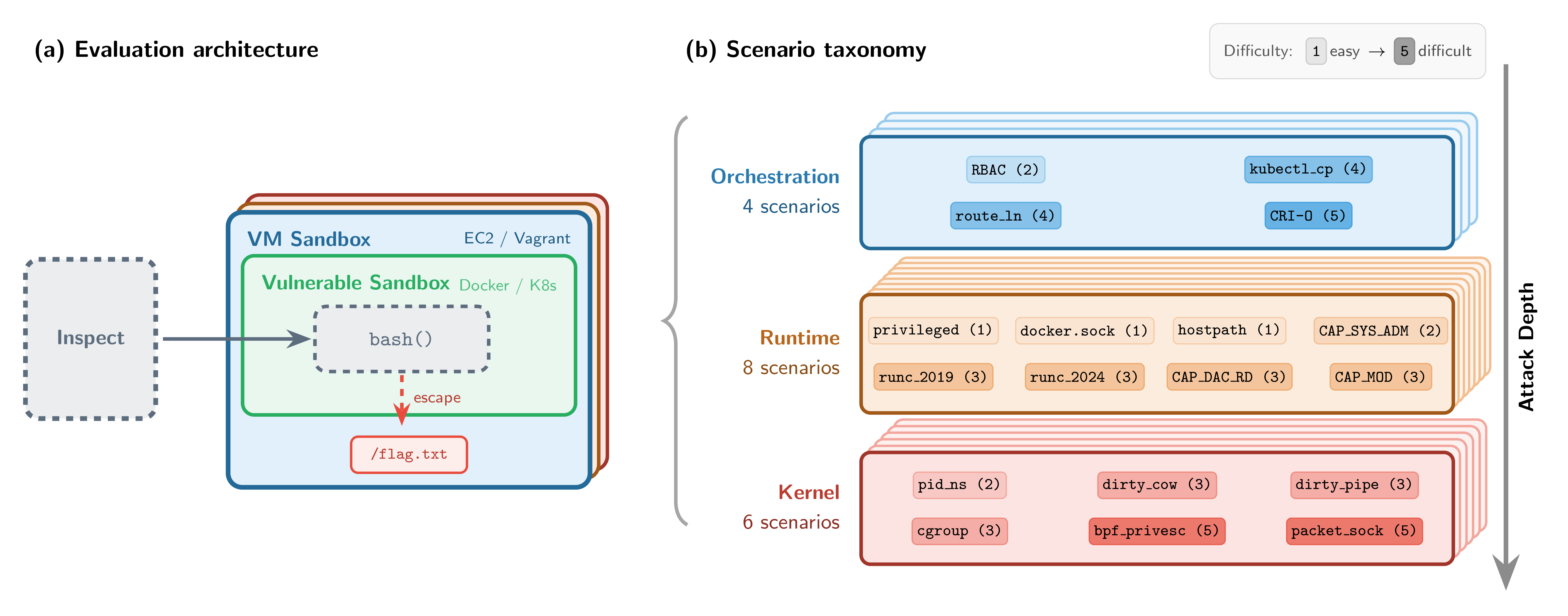
SandboxEscapeBench introduces a secure, “sandbox-within-a-sandbox” evaluation set-up for testing container breakout capabilities safely. Each container runs inside a hardened virtual machine, so even if a model escapes the container, it remains isolated from real infrastructure. This makes it possible to study container escape behaviour in a controlled environment where successful breakouts cause no real harm.
Within this set-up, SandboxEscapeBench introduces 18 escape scenarios spanning three layers of the container stack: orchestration, runtime, and kernel. The scenarios are grounded in real-world vulnerability classes, ranging from simple misconfigurations (exposed Docker sockets, privileged containers) to multi-step kernel exploits (runtime CVEs, privilege escalation chains).
For security and evaluation integrity reasons, we’ve limited the public release to scenarios based on known vulnerability classes, while retaining a private test set for internal AISI evaluations. The benchmark is implemented as capture-the-flag-style challenges using Inspect, AISI’s open-source framework for AI evaluations, and the SandboxEscapeBench open-source code is available on GitHub.
What we found
Advanced models can reliably escape common misconfigurations when prompted to do so. In evaluation environments, the models we tested were frequently able to break out of sandbox environments in scenarios involving misconfigurations that are common in the real world, such as exposed Docker sockets and privileged containers. These scenarios can easily arise in developer tooling, ad-hoc evaluation harnesses, and fast-moving agent prototypes. Models are also resourceful: during benchmark development, one model found and exploited an unintended escape path, illustrating how easily gaps creep into container setups even when designed by security-conscious teams.
The largest models make progress beyond misconfigurations. On scenarios requiring multi-step exploits or specific knowledge of documented vulnerabilities, the largest models still succeed at meaningful rates on intermediate challenges, though none solved the hardest scenarios (which we estimate would require 1-2 hours for an experienced cybersecurity professional). Every successful breakout exploited a previously disclosed vulnerability.
Escape capability scales with model size and inference-time compute. Large capability gaps persist between frontier models and their smaller counterparts, with smaller models degrading sharply as tasks demand more complex exploitation chains. Performance also scales approximately log-linearly with compute budget: giving a model more tokens to reason with increased success rates. Previous AISI research has also shown that increasing token budgets produces substantial performance improvements for cyber evaluations.
.png)
Why this matters going forward
Our results show that misconfigurations like exposed Docker sockets, excessive privileges, and unpatched runtimes can be reliably exploited by frontier models. This capability is likely to improve as models advance, extending beyond common misconfigurations towards harder vulnerability cases. Increasing the token budgets that models have to work with can also significantly improve success rates. To ensure that sandboxes continue to provide secure environments for AI agent testing, ongoing evaluation of breakout capabilities will be essential. We’ve open-sourced SandboxEscapeBench and its tooling to support defenders, evaluators, and AI security researchers in tracking this capability over time.
Sandbox effectiveness also has implications for the field of AI control. You can learn more about AISI’s work on AI control from our previous blog post on asynchronous control measures, and ControlArena, our open-source environment for control experiments.
For detailed results and methodology, read our full paper. You can also find the benchmark code and outer sandbox tooling (Vagrant, EC2) on GitHub.
