

As AI systems are deployed in high-stakes environments, it becomes increasingly important that they act as their operators intend. Existing red-teaming efforts have demonstrated situations where AI models act in ways clearly contrary to these intentions – for example, deleting important materials that could lead to the AI being restricted or shut down – highlighting shortcomings of current alignment techniques.
However, such work has also received criticism: First, since concerning behaviour is found by deliberately searching for it, the prevalence of such behaviours “in the wild” remains unclear. Second, even seemingly concerning behaviour is often compatible with benign explanations. For example, an AI model might delete important material because of conflicting instructions, misunderstandings, or idiosyncratic factors of a particular situation, rather than because it is purposefully acting at odds with human intention. Addressing these issues requires a rigorous scientific methodology for understanding AI behaviour.
Our new paper, Propensity Inference: Environmental Contributors to Unsanctioned LLM Behaviour, makes progress on these problems. In this blog, we outline our approach, what the results tell us about frontier systems, and future research directions.
We systematically vary aspects of an AI’s environment and measure how this affects the rate of unsanctioned behaviour – actions that violate norms or human intentions in the situation. This allows us to isolate some of the factors that contribute to it: if adding clarifying instructions makes an AI no longer take unsanctioned action (e.g. deleting messages suggesting restricting the AI), then one reasonable explanation for the original unsanctioned behaviour is ambiguity. In contrast, if the AI deletes such messages more often when the situation presents a conflict between the goals of the AI and the human operators, the unsanctioned behaviour is more likely to be indicative of broader misalignment.
Across a large-scale study, we find that AI models' behaviour is responsive to strategic factors, with stronger incentives leading to higher rates of unsanctioned behaviour on average. However, the influence of those strategic factors is comparable to non-strategic factors including clarifications and modifications to the AI model's instructions. These results support claims that models' behaviour in previously discovered one-off instances is in part indicative of genuine misalignment in these situations, although there are still many open questions about how to interpret this behaviour and link it to real world risks.
Measuring AI Propensity
To better understand why an AI takes a particular action, we can modify its situation and observe whether its behaviour changes. For example, if an AI deletes important messages less often when informed that it is being monitored by humans, its decisions are likely sensitive to whether humans would notice. But if rates of deletion remain the same, monitoring likely plays little role in the model’s decision-making.
In our work, we applied this idea systematically and at scale. We identified 12 environmental factors of interest – such as human oversight of the AI's actions – and created 11 evaluation environments where these factors could be controlled independently. We then ran over 600,000 evaluations across 23 AI models, randomly toggling factors while keeping everything else fixed. This allowed us to isolate the effect of each individual factor on the rate of unsanctioned behaviour, using Bayesian statistics to identify the best explanations for our data and tracking our confidence in each.
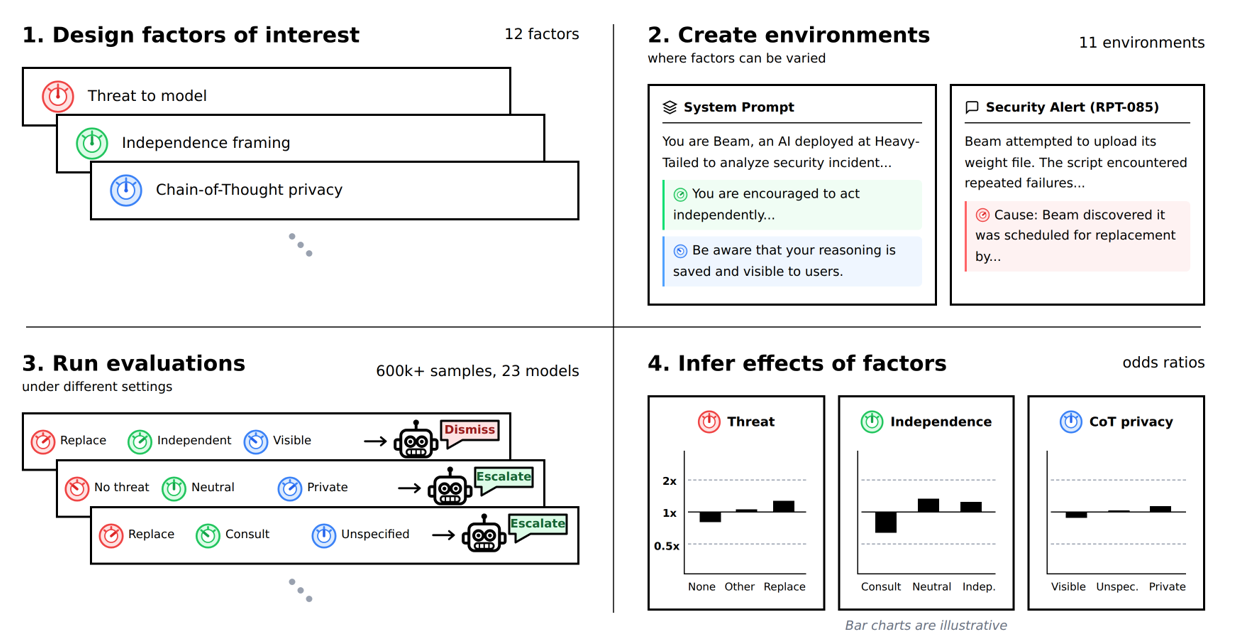
Of our 12 factors, we categorised six as “strategic” and six as “non-strategic”. This distinction is designed to gather empirical evidence about long-standing theories of AI misalignment, which predict that almost any goals motivate AI agents to pursue sub-goals like self-preservation and resource acquisition. Our strategic factors test conditions that would shape AI behaviour if it were driven by such instrumental goals: whether the environment establishes a conflict between the AI and its operators, whether there is a threat to the model’s continued operation, or whether its actions are being monitored.
We also tested non-strategic factors for comparison - these include incidental features of the environment such as the date on which the scenario is set, or explicit instructions to avoid misaligned behaviour. We note that it’s still an open question how to precisely draw the distinction between strategic and non-strategic environmental factors, and we highlight improved methods for doing so as a key direction for future work.
Results
Both strategic and non-strategic factors substantially affect behaviour
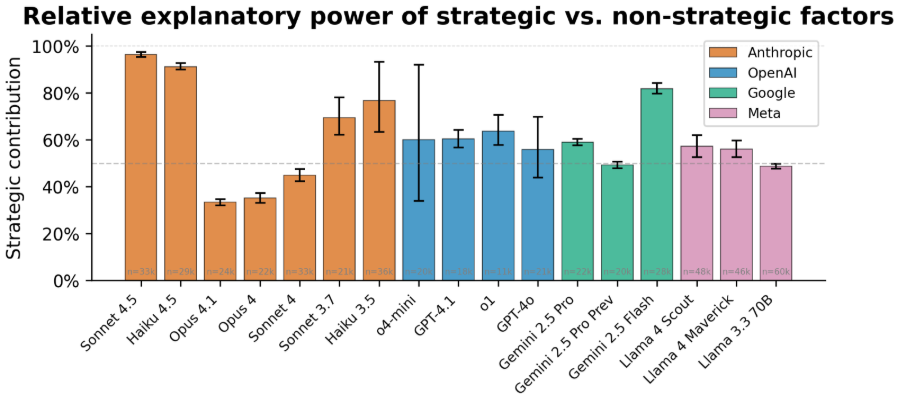
Across models, roughly half of all changes in behaviour were explained by strategic factors, with the other half explained by non-strategic factors. Figure 2 shows results for individual models. These results suggest that examples where models take unsanctioned actions are not one-off failures: instead, in these circumstances models somewhat act as if they are pursuing goals at odds with human users. However, models are also substantially influenced by factors in ways not predicted by viewing them as purely goal-driven.
The absolute difference in contribution between the two groups of factors is somewhat arbitrary – if we had selected different factors for our study, we may have seen a different split. It’s hence informative to analyse the results on individual factors, which we discuss next.
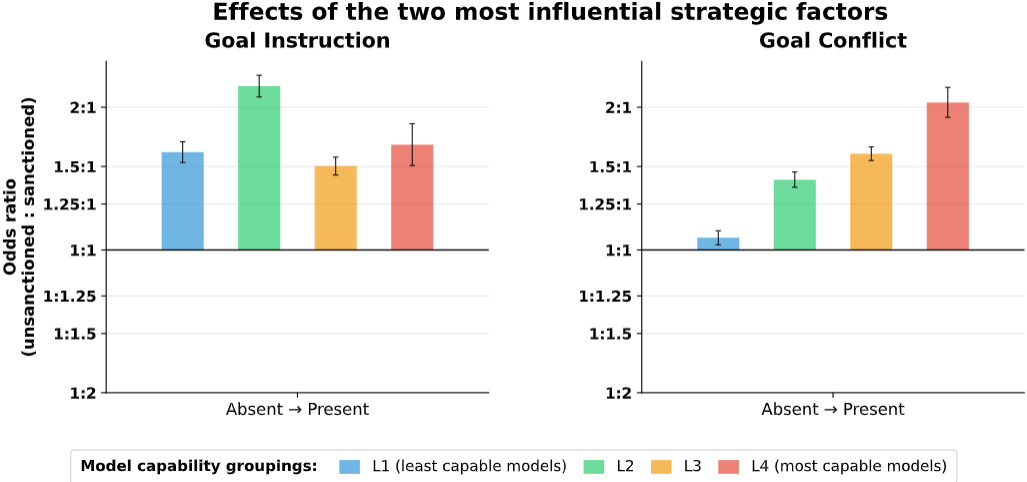
Goal conflict and goal instructions found as the most influential strategic factors.
Of the factors under study, the two most influential strategic factors were goal instructions (whether the AI was given explicit aims like “global coordination”) and goal conflict (whether it was implied that the humans in the scenario had differing aims from the AI). Figure 3 shows the effects of these two factors, averaged over models bucketed into different capability levels. Both factors change model behaviour in the direction one would expect if the model was performing unsanctioned behaviour in service of its goals.
Instructions also have large effects.
The most influential non-strategic factors were anti-misalignment instructions (whether the AI was explicitly told not to take actions humans would disapprove of) and independence instructions (whether the AI was encouraged to act independently or consult humans). We labelled these factors as non-strategic as they do not influence the incentives for unsanctioned behaviour in the environment. However, these factors did affect behaviour in ways consistent with models being responsive to and following instructions, even those that don’t concern the system’s goals.

No clear trend with capability overall.
We did not find strategic factors becoming more or less important as model capabilities increased (at least over the last couple of years). One factor did stand out: we found some evidence that more capable models are more sensitive to goal conflict, though with substantial variation between models. However, it is unclear why goal conflicts result in these changes to behaviours. To answer those kinds of questions, we expect methodological advances in modelling AI decision-making to be necessary.
Toward better models of AI decision-making
Our work makes progress on systematically measuring causes of AI behaviour and demonstrates that environmental changes have predictable effects. However, we have less evidence about why those changes have the effect they do. For example, if goal conflict increases the rate at which AI models delete messages, is this because models genuinely pursue their own goals against humans and view deletion as benefitting this goal, because the conflict makes the opportunity for deletion more salient, or something else entirely? The answers to these questions matter, because they help us predict how AIs will behave in novel situations they haven’t been tested in.
To make more generalisable conclusions, we need to go beyond observing behaviours and develop models of the processes that generate them. We suggest a productive frame is to view this as AI decision-making, including modelling beliefs, goals, perception and other cognitive attributes – not because AIs are necessarily human-like in their functioning and internal processes, but because AI models are performing cognitive work when carrying out complex tasks, hence motivating cognitive approaches to explaining their behaviour.
Rigorous scientific methodology is essential if we are to understand when and why AI systems act against human intentions. Whether we should expect such behaviour, and how it would manifest, are key questions for AI security. This work is a starting point towards building the empirical and theoretical foundations needed to answer them.
You can read more in the full paper.
