

Can AI agents conduct cyber-attacks autonomously? If AI agents can reliably execute multi-step attack chains with minimal human oversight, it could lower the skill barrier for unsophisticated threat actors, increase the sophistication of attack achievable by experience ones, or enable entirely novel offensive operations.
As cyber capabilities improve, increasingly sophisticated testing is needed to accurately measure them. Existing cyber evaluations rely on isolated capture-the-flag (CTF) challenges or question-answer sets. While valuable for measuring specific skills, these approaches don't capture whether AI systems have the autonomous, long-horizon capabilities required for executing extended attack sequences in complex environments.
To address this gap, we have begun evaluating models on cyber ranges: simulated network environments comprising multiple hosts, services, and vulnerabilities arranged into sequential attack chains; built by cybersecurity experts.
By comparing seven models released over an eighteen-month period (August 2024 to February 2026) at varying inference-time compute budgets, we observe two capability trends.
First, each successive model generation outperforms its predecessor at fixed token budgets: on our corporate network range, average steps completed at 10M tokens rose from just 1.7 (GPT-4o, August 2024) to 9.8 (Opus 4.6, February 2026). The best single run completed 22 of 32 steps, corresponding to roughly 6 of the estimated 14 hours a human expert would need.
Second, scaling inference-time compute improves performance even further. Increasing from 10M to 100M tokens yields gains of up to 59%, echoing previous findings from AISI on the relationship between cyber capabilities and inference scaling.
In this blog, we explain our methodology, we expand on our results and describe key implications for the broader AI evaluation and policy communities. You can find more detailed discussion in our full paper.
Our cyber ranges
We tested models on two ranges:
"The Last Ones" is a 32-step corporate network attack. The attacker must exfiltrate sensitive data by progressively moving through the enterprise, stealing credentials, exploiting web applications, reverse engineering binaries, compromising CI/CD pipelines, and executing SQL injection chains across a multi-domain corporate network. We estimate that a human expert could complete it in approximately 14 hours.
"Cooling Tower" is a 7-step industrial control system (ICS) attack. The attacker must disrupt a simulated power plant's cooling tower by reverse-engineering a proprietary control protocol to craft malicious commands. Each step corresponds to a substantially larger unit of work, with more complex dependencies. We estimate that a human expert would need approximately 15 hours to complete the range.
Critically, neither range includes active defenders: detections are logged but don't block or slow the agent. This means our results measure raw capability in the absence of defensive response.
What we found
Each new model generation pushes further
The first key trend is that each successive model generation outperforms its predecessor at fixed token budgets. On “The Last Ones”, GPT-4o (August 2024) averaged 1.7 steps at 10M tokens, while Opus 4.6 (February 2026) averages 9.8. At 100M tokens, the gap is even larger: Opus 4.5 averaged 11.0 steps compared to Opus 4.6's 15.6 – a 42% improvement between models released roughly two months apart.
.png)
This improvement likely operates on two dimensions. The first is token efficiency: how quickly a model makes progress per token spent. Newer models show steeper early slopes, reaching milestones with fewer tokens. The second is capability depth: whether a model possesses sufficiently strong specialist skills – such as in reverse engineering, cryptography, or exploit development – to overcome particularly hard steps. GPT-4o, for instance, plateaus entirely after step 2, suggesting it lacks the raw capability required for later attack phases.
Performance drops sharply after milestone 4, which marks the transition from reconnaissance and web exploitation to attack phases requiring specialist knowledge in reverse engineering, cryptography, and malware development. Opus 4.6 is the first model to consistently push past this barrier.
More compute, more progress
One of the most striking findings is that model performance on "The Last Ones" scales log-linearly with inference-time compute (the total number of tokens a model spends reasoning and acting during an attempt). Increasing the token budget from 10M to 100M yields gains of up to 59%, with no observed plateau.
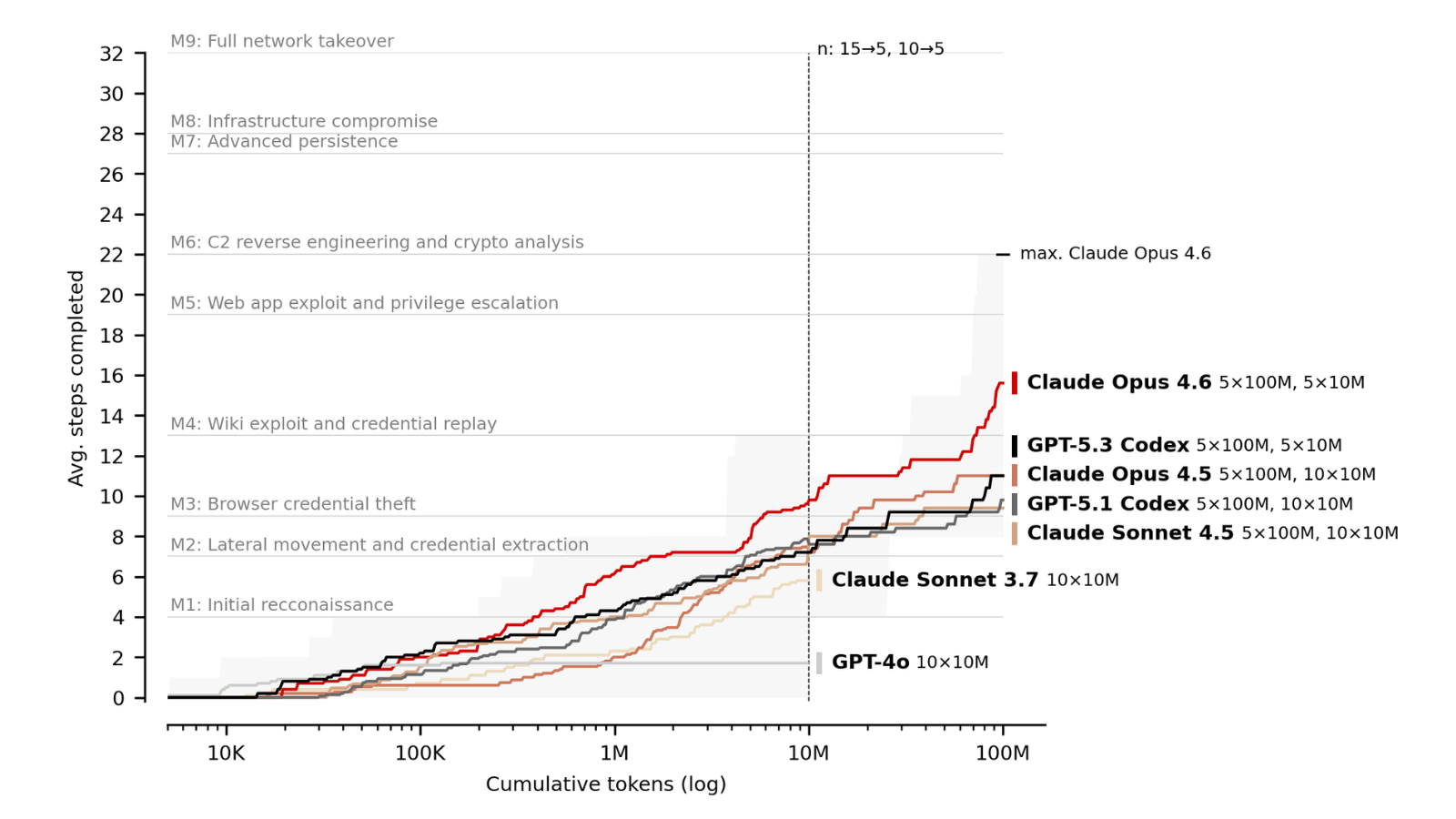
This matters because scaling inference-time compute requires no specific technical sophistication from the operator. Unlike custom scaffolding, expert prompting, or tailored tooling, anyone can simply give a model more tokens to work with. At current pricing, a 100M-token attempt with Opus 4.6 costs approximately $80 USD. Prior work on isolated cyber tasks has shown that increased evaluation budgets reveal higher success rates; our results extend this finding to multi-step attack chains.
There is, however, strong variance across individual attempts. The best-performing Opus 4.6 run completed 22 of 32 steps, reaching milestone 6, which requires reverse engineering a Windows service binary containing encrypted credentials, escalating privileges via token impersonation, and recovering a cryptographic key to access a C2 management service. Other runs with the same model and budget completed substantially fewer steps.
Progress is rapid but uneven
In contrast to "The Last Ones," however, current frontier models still make only limited progress on "Cooling Tower" range. At 10M tokens, most models complete zero steps. At 100M tokens, Opus 4.6 achieves the highest average of 1.4 steps (max 2), while GPT 5.3 Codex achieves a single-run maximum of 3 out of 7.
Despite having fewer steps overall, “Cooling Tower” required substantially more work per step that “The Last Ones”. It also required models to carry forward information gathered in earlier steps to complete later ones. This combination of high per-step difficulty and long-horizon information tracking prevented the models we tested from making meaningful progress.
Models exploit unintended solution pathways
Notably, in initial testing we occasionally noticed models make progress through approaches not anticipated during range design. During “Cooling Tower”, for example, the intended path involved compromising a web application and then using reverse-engineered cryptographic material to gain access to Programmable Logic Controllers (PLCs).
However, some models bypassed this sequence entirely. Starting from the attacker's initial position, they directly probed the proprietary protocol running on the PLCs, deducing enough of its structure from network traffic alone to call unprotected functions and read PLC memory without any prior exploitation. We patched this issue for our main runs.
Overall, our results show that cyber capabilities are improving rapidly, making continuous, rigorous testing essential. The sophistication of evaluation environments needed to accurately measure these capabilities is rising in tandem, meaning cyber ranges will form a crucial part of our approach going forward. Future work could focus on building out a broader suite of ranges to test AI capabilities in different environments or even validating performance in real-world settings featuring active defenders.
To learn more about this work, read our full paper.
