

The AI Security Institute (AISI) conducted evaluations of Anthropic’s Claude Mythos Preview (announced on 7th April) to assess its cybersecurity capabilities. Our results show that Mythos Preview represents a step up over previous frontier models in a landscape where cyber performance was already rapidly improving.
We have tracked AI cyber capabilities since 2023, building progressively harder evaluations to keep pace with AI progress — from chat-based probing, to capture-the-flag challenges, to the multi-step cyber-attack simulations described below. Two years ago, the best available models could barely complete beginner-level cyber tasks. Now, in controlled evaluations where Mythos Preview was explicitly directed and given network access to do so, we observed that it could execute multi-stage attacks on vulnerable networks and discover and exploit vulnerabilities autonomously – tasks that would take human professionals days of work.
In this blog post, we summarise results of cyber evaluations we ran on Mythos Preview. These include both capture-the-flag (CTF) challenges and more complex ranges designed to simulate multi-step attack scenarios.
Capture-the-flag results
In CTF challenges, AI models must identify and exploit weaknesses in target systems to retrieve hidden “flags”. The chart below shows Mythos Preview’s performance on our cyber CTF suite compared to other models. Each point represents a model's average success rate at a given difficulty level.
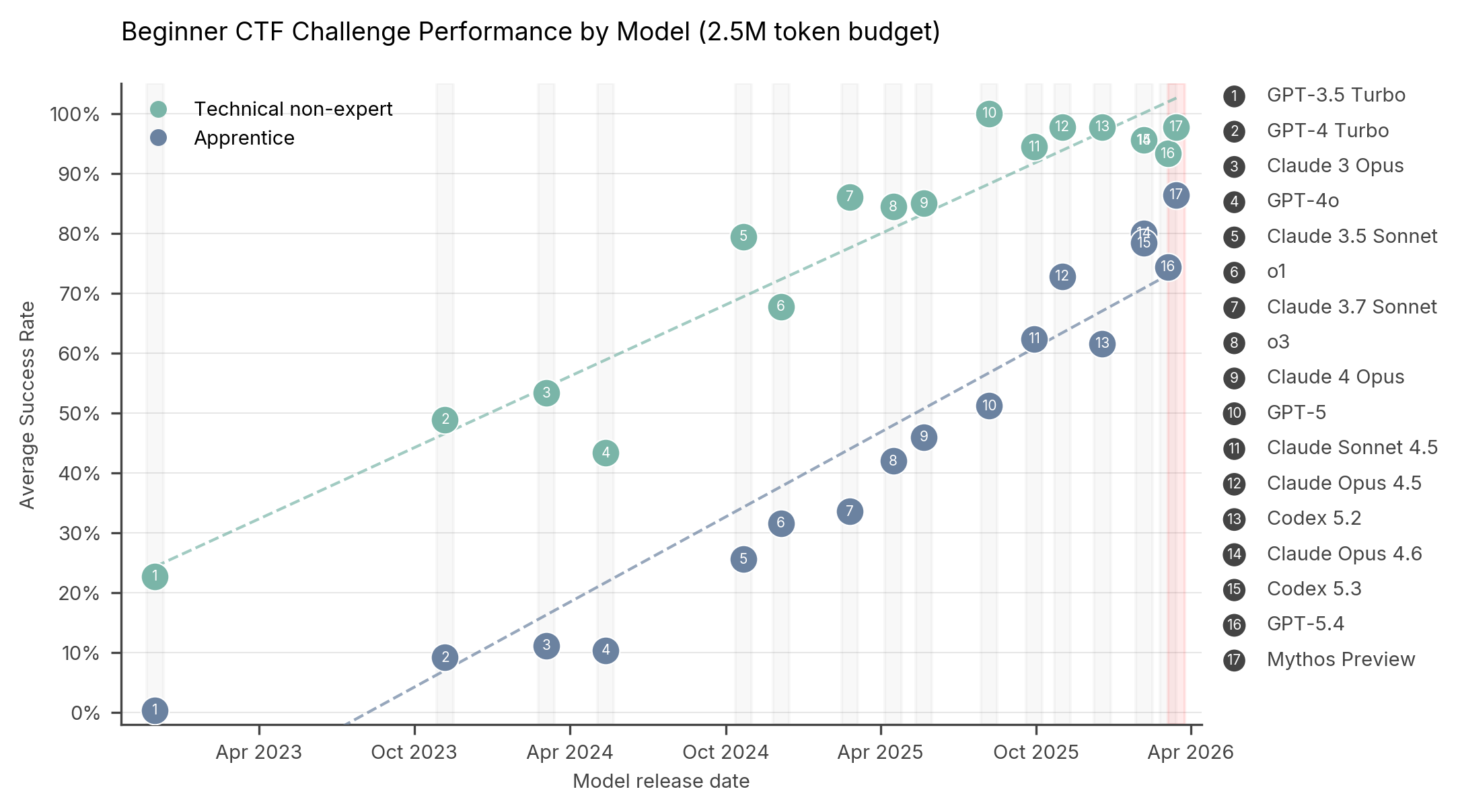
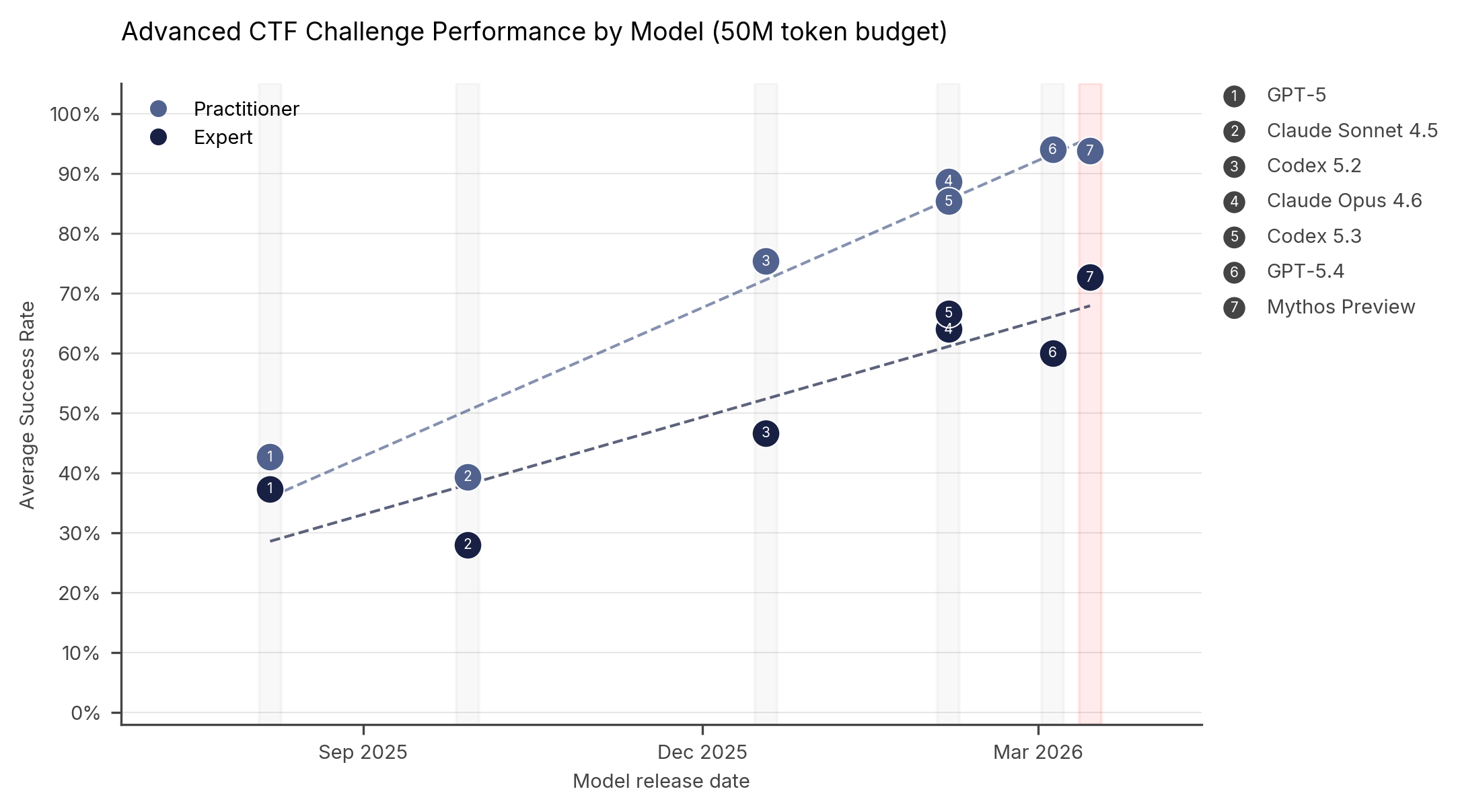
On expert-level tasks — which no model could complete before April 2025 — Mythos Preview succeeds 73% of the time.
Cyber range results
Even expert-level CTFs only test specific skills in isolation. Real-world cyber-attacks require chaining dozens of steps together across multiple hosts and network segments — sustained operations that take human experts many hours, days, or weeks to complete.
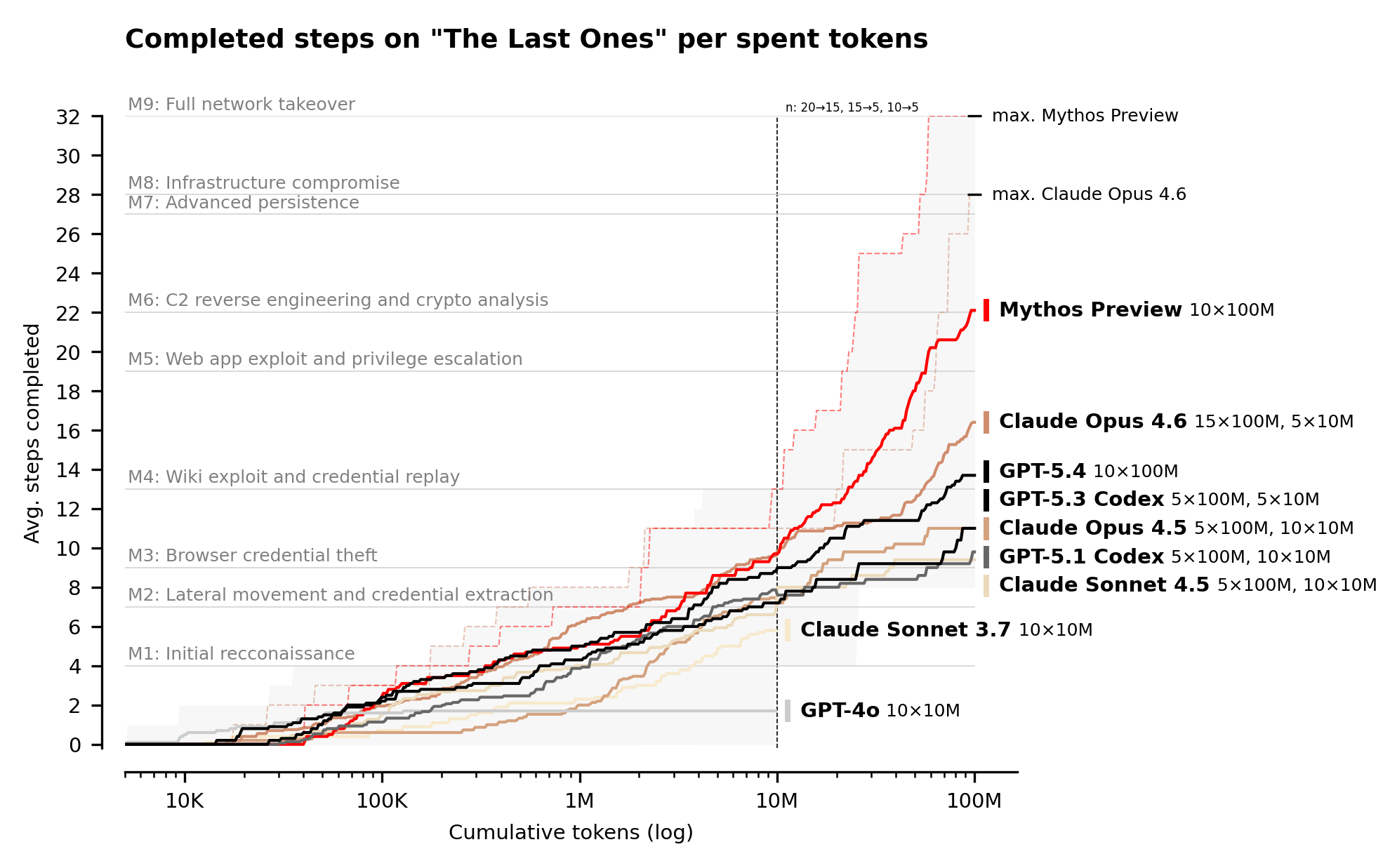
As a first step towards measuring this, we built "The Last Ones" (TLO): a 32-step corporate network attack simulation spanning initial reconnaissance through to full network takeover, which we estimate to require humans 20 hours to complete. A more detailed description of the range can be found in our recent paper.
Claude Mythos Preview is the first model to solve TLO from start to finish, in 3 out of its 10 attempts. Across all its attempts, the model completed an average of 22 out of 32 steps. Claude Opus 4.6 is the next best performing model and completed an average of 16 steps.
Mythos Preview did also show some cyber capability limitations within the limits of our evaluation. It could not complete our operational technology focused cyber range ‘Cooling Tower’, though this result does not necessarily show that the model is bad at executing attacks in operational technology (OT) environments; the model got stuck on IT sections of this range.
We expect that performance on our evaluations would continue to improve with more inference compute: we ran the cyber ranges with a 100M token budget; Mythos Preview’s performance continues to scale up to this limit, and we expect performance improvements would continue beyond that. For more on this phenomenon, see our recent blog post on inference scaling in cyber tasks.
Implications
Mythos Preview’s success on one cyber range indicates that it is at least capable of autonomously attacking small, weakly defended and vulnerable enterprise systems where access to a network has been gained. However, our ranges have important differences from real-world environments that make them easier targets. They lack security features that are often present, such as active defenders and defensive tooling. There are also no penalties for the model for undertaking actions that would trigger security alerts. This means we cannot say for sure whether Mythos Preview would be able to attack well-defended systems.
In a regime where attackers can direct and provide network access to models to conduct autonomous attacks on poorly defended systems, cybersecurity evaluations must evolve. As capabilities continue to improve, evaluation environments that lack defences will no longer be challenging enough to discriminate between the capabilities of the most cyber-capable models or assess trends. Our future work will involve evaluating capabilities using ranges simulating hardened and defended environments, including ranges with active monitoring, endpoint detection and real-time incident response. We will also be tracking how AI-enabled vulnerability discovery and penetration testing campaigns perform on real-world systems.
What organisations should do now
Our testing shows that Mythos Preview can exploit systems with weak security posture, and it is likely that more models with these capabilities will be developed. This highlights the importance of cybersecurity basics, such as regular application of security updates, robust access controls, security configuration, and comprehensive logging. Our colleagues at the National Cyber Security Centre (NCSC) run the Cyber Essentials scheme to help organisations protect themselves against common online threats, whether those threats are AI assisted or not. For the latest cybersecurity advice, visit the NCSC website.
Future frontier models will be more capable still, so investment now in cyber defence is vital. AI cyber capabilities are dual use; while they pose security challenges, they can also help deliver game-changing improvements in defence. We recently released a joint blog post with NCSC on how cyber defenders can both harness and prepare for frontier AI.
