

The safety of advanced AI systems increasingly depends on the ability to oversee them: to audit models for concerning propensities before deployment, to monitor their behaviour during use, and to investigate incidents after they occur. As AI systems take on more autonomous, long-horizon tasks, the quality of oversight will determine how much we can trust them.
In a new report, we map the current landscape of AI oversight, and how it is likely to change. The report draws on 25 expert interviews across frontier AI developers, government, NGOs, and academia, together with a literature review and independent analysis of pathways to the degradation of oversight. We identify current oversight methods, and the properties of current AI systems that these methods rely on. We also examine the pathways by which they could degrade, and the technical levers available to preserve them.
Both the literature and expert opinion support the conclusion that current oversight rests on foundations that are likely to erode, and emerging methods are not yet mature enough to compensate for this erosion. However, there are practical interventions available now: developers can take steps to preserve current oversight channels and invest in emerging techniques as fallbacks for when they degrade.
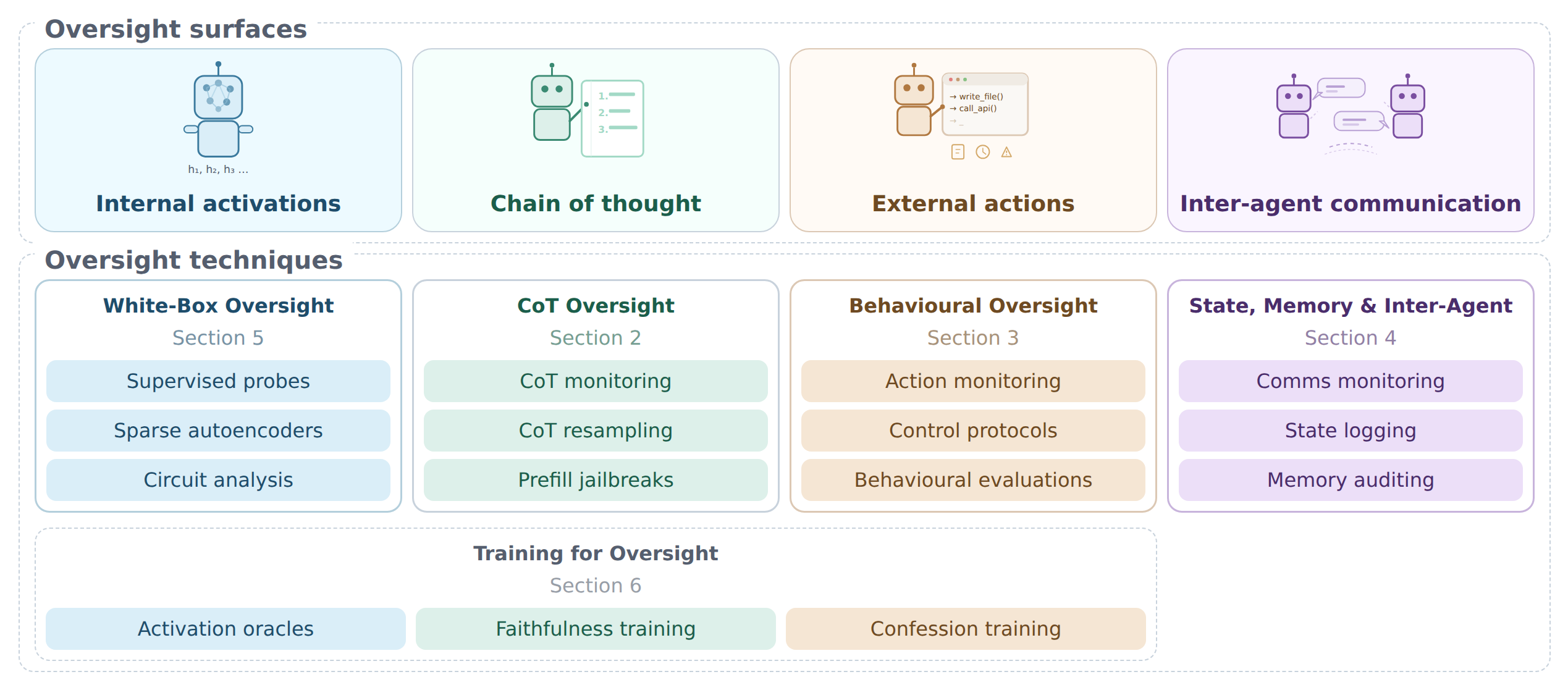
Pressures across oversight surfaces
The report identifies four oversight surfaces:
- Internal activations – the signature of an AI model’s internal computations
- Chain-of-thought – the “thinking” text an AI system produces when processing a task
- External actions – how the system acts on the external world
- Inter-agent communication – the interaction channels between different AI systems
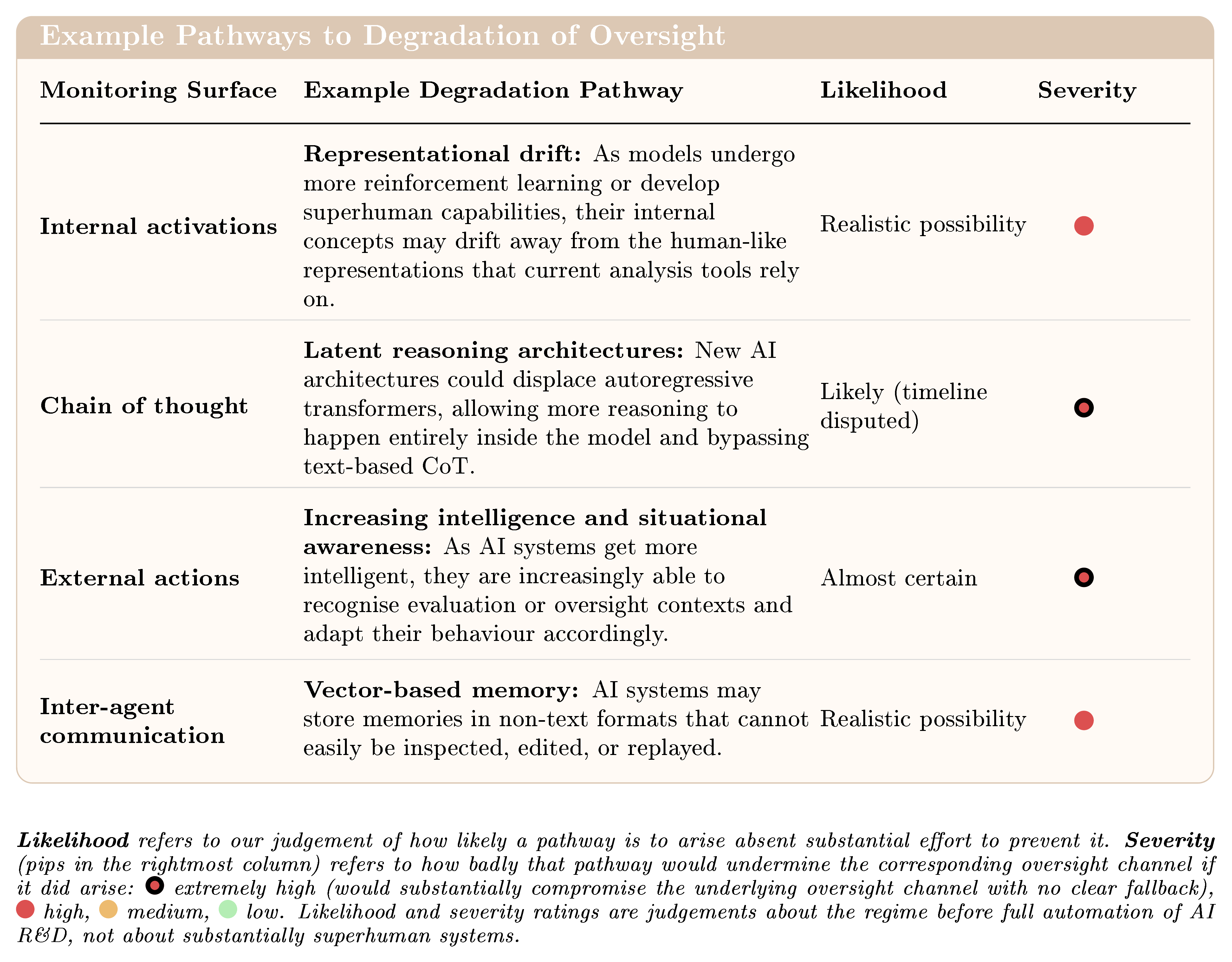
We then examine how these oversight surfaces might degrade moving forwards. See Figure 2 for some examples of degradation pathways:
Expert disagreement
An important part of mapping the oversight landscape was surfacing and exploring disagreements between experts. Some examples of disagreements:
- Whether latent reasoning architectures will take over. Latent reasoning architectures let a model do its reasoning entirely inside its internal state, rather than 'thinking out loud' in text humans can read. If latent reasoning architectures replace today's text-based reasoning, one of the strongest sources of oversight we currently have disappears.
- Whether action monitoring and control will be sufficient for harm prevention. Action monitoring only observes what a model does, not how it reasons. Control protocols add safeguards beyond action-only monitoring, such as blocking, rolling back, or resampling suspicious outputs. This question affects how much developers can rely on these deployment-time safeguards, versus needing stronger upfront evidence that the model itself is aligned.
- Whether evidence from misalignment honeypots is meaningful. Alignment honeypots are controlled scenarios designed to surface a model's misaligned behaviours before deployment. This question affects how much weight current alignment tests can carry when supporting decisions about whether a model is safe to deploy.
- Whether training for oversight will generalise to deployment contexts. Training for oversight means training the model itself to support oversight, e.g. to be honest, or to make its reasoning more transparent. This question affects whether those behaviours hold up in real-world use, or only in the training environment.
The overall picture
Existing oversight techniques largely work well for today's AI systems, and benefits can still be gained by applying them. Developers draw on a portfolio of techniques, such as monitoring model actions, reading models' chain-of-thought reasoning, running behavioural evaluations, and probing internal activations. However, the properties of today's AI systems that make these techniques work, such as text-based reasoning, limited ability to game evaluations, and human-interpretable internal representations, are contingent and may not hold as systems are developed further.
The report identifies more than twenty distinct pathways by which current oversight could degrade. Some pressures are already visible: for example, frontier models are increasingly able to recognise when they are being tested and adjust their behaviour. Others, such as architectures that enable reasoning in hidden internal states, would severely weaken current monitoring if they emerged. These pressures could compound, and because many oversight-relevant properties are not routinely tracked, some loss of oversight could go unnoticed.
Our full report outlines opportunities for developers and deployers to actively preserve currently available oversight, measure exposure to oversight degradation, and invest in developing emerging oversight techniques.
You can see the full report here.
Are you excited about this type of work? Join us!
If you’re a Research Scientist or Research Engineer, we’re hiring – apply here and come and work with us!
