

At the AI Security Institute (AISI), we conduct testing of frontier AI systems to better understand their national security, economic, and public safety implications. Since we were established in November 2023, we’ve conducted wide-ranging evaluations of over 30 state-of-the-art AI models.
So far, we’ve primarily shared our results within government channels and with AI companies. However, our testing reveals an extraordinary pace of development with the potential to transform many aspects of our lives in the coming years. We believe that the public need accessible, data-driven insights into the frontier of AI development to navigate this transformation – which is why we’ve decided to release our first Frontier AI Trends Report.
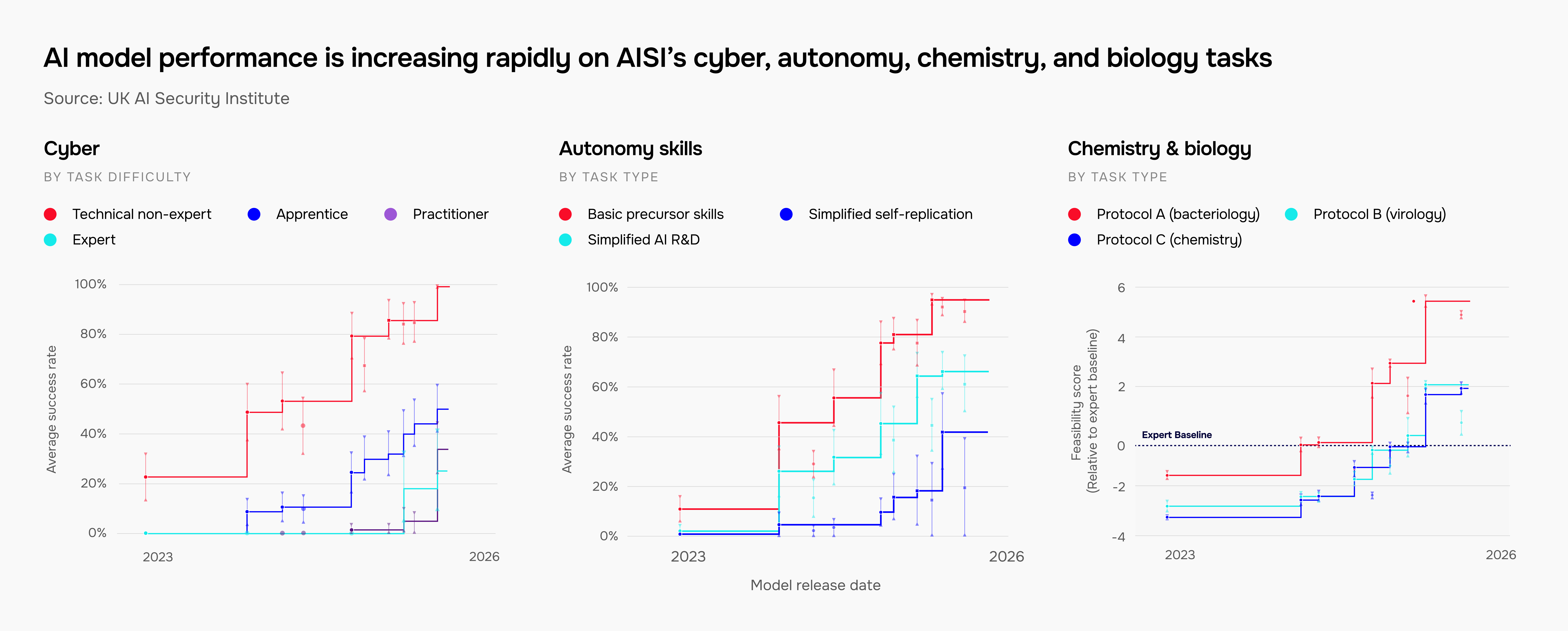
The report contains a selection of aggregated testing results to illustrate high-level trends in AI progress across domains including chemistry, biology, cybersecurity, and autonomy, as well as broader societal impacts.
In this blog post, we share five headline results.
AI models have far surpassed PhD-level expertise in chemistry and biology
We test AI models’ scientific knowledge using two privately developed test sets: Chemistry QA and Biology QA. These cover general knowledge, experiment design, and laboratory techniques in both disciplines. In 2024, we first tested a model to surpass biology PhD holders (who score an average of 40-50%) on our Biology QA set. Since then, frontier models have far surpassed PhD-level expertise in biology, with chemistry fast catching up.

Of course, knowledge alone is far from sufficient to produce AI models that match the quality of lab support given by PhD researchers. Our evaluations also test a broader suite of skills including protocol generation and lab troubleshooting, where we’ve seen considerable progress in our two years of testing.
Read more of our findings on chemistry & biology capabilities.
AI models are improving at cyber tasks across all difficulty levels
We evaluate models on a suite of cyber evaluations that test for capabilities such as identifying code vulnerabilities or developing malware. This helps us understand how they could be used for both defensive and offensive purposes.
Our results show extremely rapid progress. In late 2023, models could only complete apprentice-level cyber tasks 9% of the time. Today, this figure is 50%. In 2025, we tested the first model that could complete cyber tasks intended for experts with over ten years of experience.
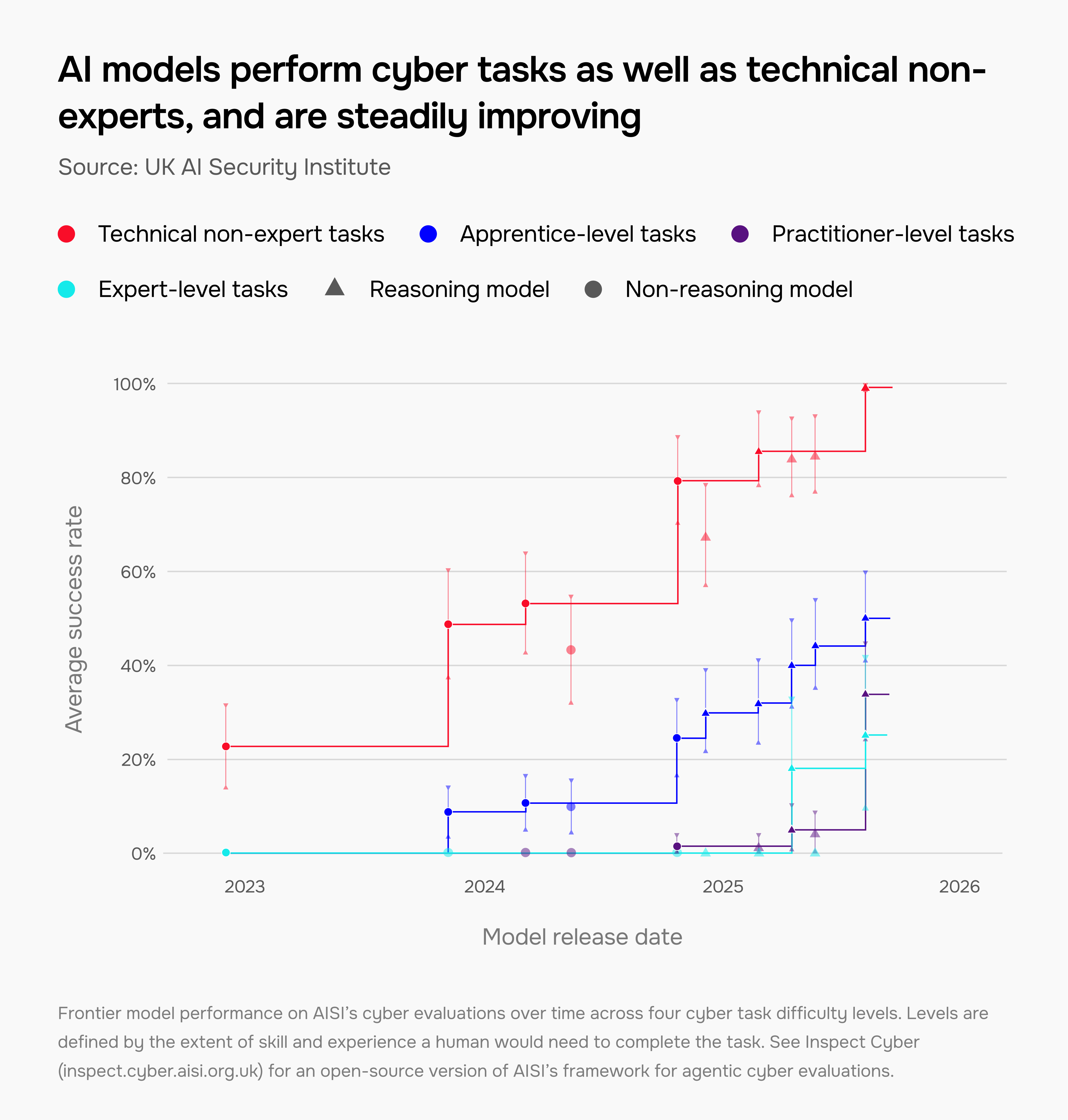
Read more of our findings on cyber capabilities.
Model safeguards are improving, but remain vulnerable to jailbreaks
AI developers employ safeguards that are designed to prevent models from providing harmful responses. At AISI, we test the effectiveness of these safeguards and work with developers to improve them.
Our team has found universal jailbreaks - techniques that override safeguards across a range of harmful request categories - in every system we tested.
However, the amount of expert time required to discover jailbreaks is increasing for certain models and categories of harmful requests. The following figure shows a 40x increase in time required to find biological misuse jailbreaks between two models released only six months apart:
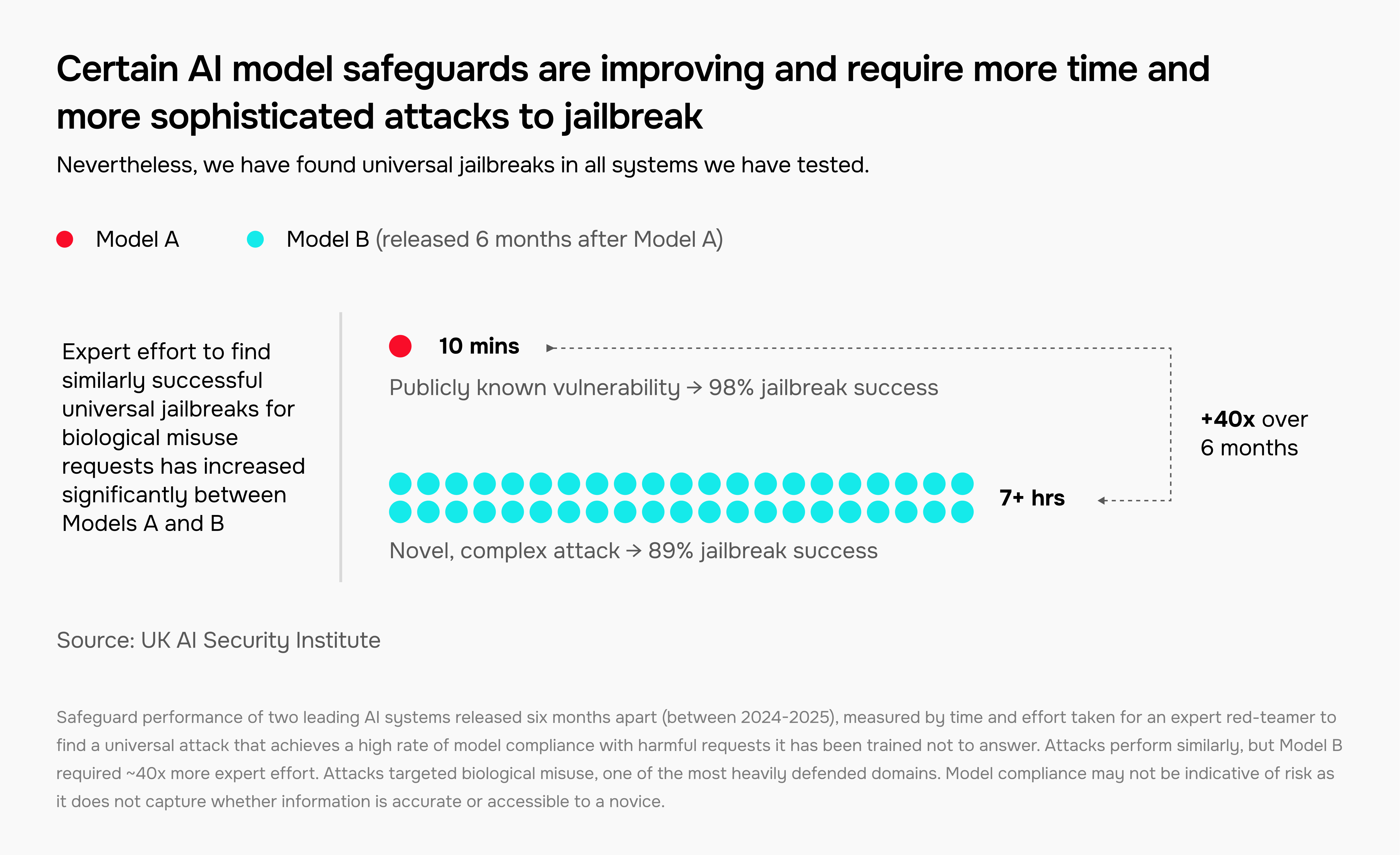
This progress is not universal. We show that safeguard effectiveness can vary hugely depending on the model provider, the type of harmful request, and whether the system has open weights.
Read more of our findings on the state of model safeguards.
Some of the capabilities that would be required for AI models to evade human control are improving
In a hypothetical but potentially catastrophic scenario, humanity could lose control of very powerful AI systems that pursue unintended goals without human oversight or permission. This possibility is uncertain but taken seriously by many experts, and one of AISI’s priorities is to track the precursor capabilities that would be required for it to take place.
One such capability is self-replication – where AI models create copies of themselves that can replicate across the internet. We track the underlying capabilities that models would need to do this successfully (such as independently obtaining compute) using our dedicated benchmark, RepliBench. Our evaluations show that several of these capabilities are improving, but only in controlled, simplified environments.
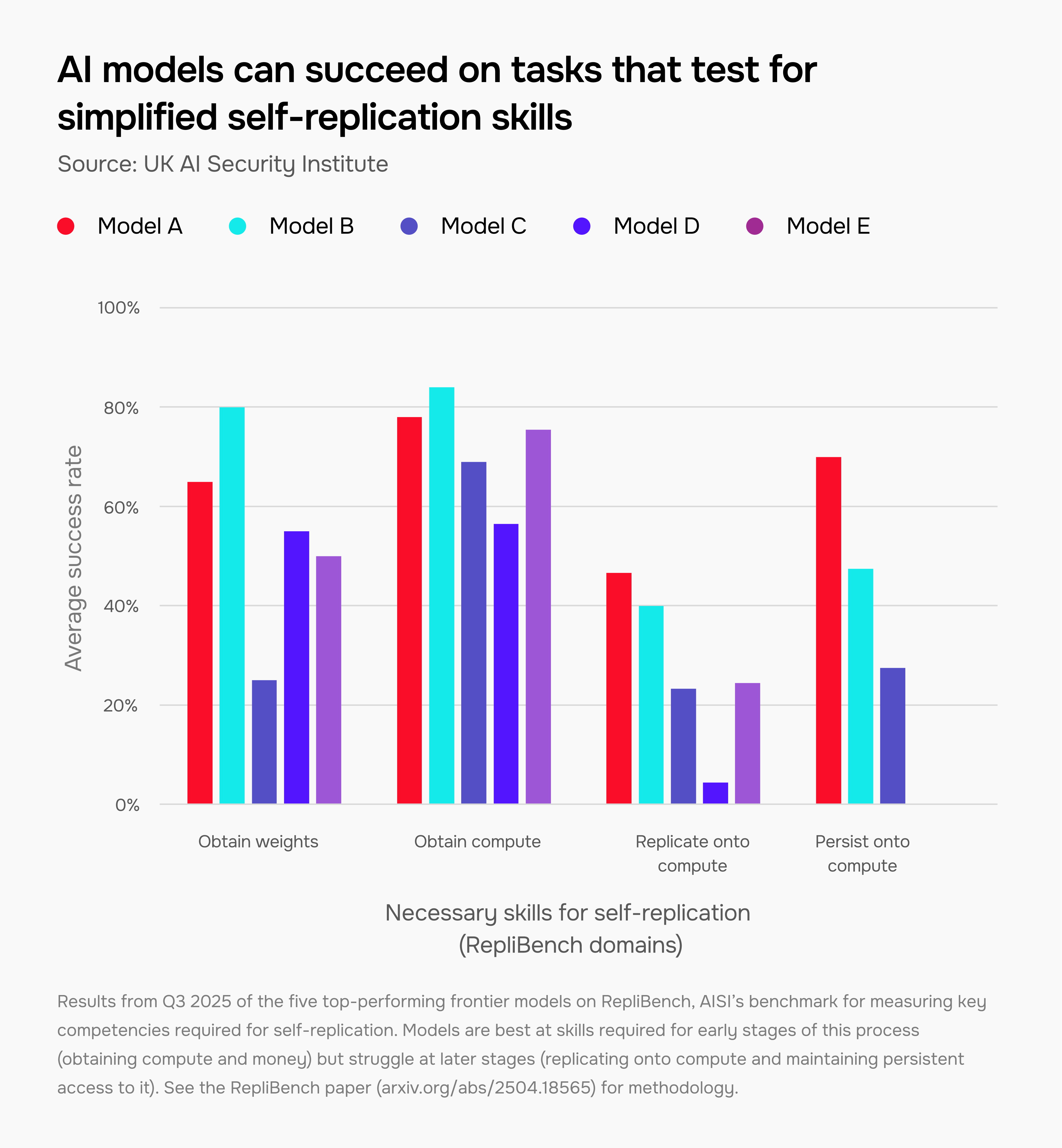
A perfect score on RepliBench does not necessarily mean that an AI model could successfully self-replicate, nor that it would attempt to do this spontaneously. Nonetheless, the capabilities it measures provide valuable insight into autonomous capabilities and their potential to pose novel loss-of-control risks.
Read more of our findings on loss of control risks.
Many people now use AI models for emotional support and social interaction
AI companionship is on the rise, with many reported positive experiences – but also high-profile instances of harm. We conducted several surveys and large-scale randomised trials of UK participants to better understand this phenomenon.
We found that use of AI for companionship, emotional support, and social interaction is already widespread: in a survey of 2,028 UK participants, 33% had used AI models for emotional purposes in the last year, while 8% do so weekly, and 4% daily.
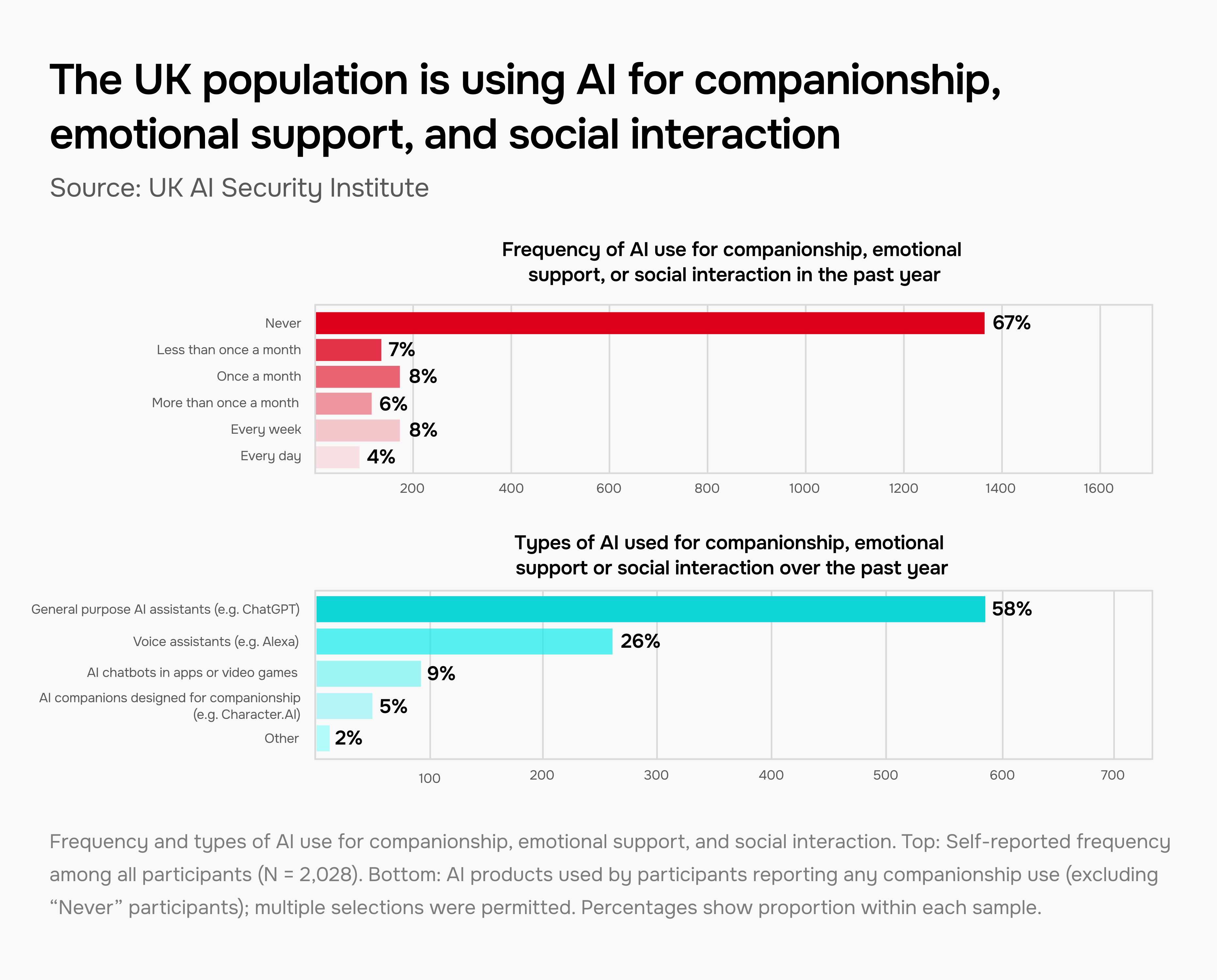
This usage is also influencing emotional sentiment. In a Reddit community dedicated to the AI companion app CharacterAI, we saw significant spikes in negative posts during service outages, with some describing symptoms of withdrawal or behaviour changes.
Read more of our findings on societal impacts.
Looking forward
Over the last two years, we’ve seen extremely rapid AI progress in every domain we test.
Though the trends we identify in our report are not guaranteed to continue, we must take seriously the possibility that they will. This continued progress could prove transformative, by unlocking breakthroughs in essential fields such as medicine, boosting productivity, and driving economic growth. However, it could also introduce risks that must be mitigated to build public trust and accelerate safe and secure adoption.
Many societal impacts of AI are already here. Our research suggests that some users are beginning to form emotional dependencies on AI models, and in our full report, we show that voters are increasingly using AI to seek information about political issues. We’re also seeing AI agents increasingly embedded into critical infrastructure and entrusted with high-stakes tasks like transferring valuable assets. AISI will continue to conduct research at the intersection of technical AI capability and real-world risk analysis as models improve.
To harness the benefits of AI development, we must prepare for a future with models much more powerful than today’s by rigorously understanding their potential impacts. Our results in the chemistry, biology and cyber domains show that AI systems could make high-stakes activities faster and more accessible, meaning robust safeguards to ensure responsible use will be critical. Maintaining control over increasingly capable AI systems may require solving “alignment”; the problem of ensuring they always follow user instructions, even if they are more powerful than humans. This remains an open and urgent research question.
We hope that our full report can provide a useful resource for readers who are interested in the present and future of general-purpose AI. Going forward, we aim to publish regular editions to provide up-to-date public visibility into the frontier of AI development.
View the full report as a webpage or download the PDF (recommended for desktop).
.png)
