

As AI agents are given more autonomy and harder tasks, underestimating their capabilities becomes more consequential. Most agent evaluations still reduce capability to a single number: a benchmark score, a pass/fail, or the length of task an agent can finish. That number hides a key design choice: how much compute the agent is allowed to spend before stopping.
In March 2026, AISI published results suggesting that modest compute limits understate model capability on cyber tasks, and that the same limits may now miss substantial gains. Our Science of Evaluation team has since run frontier models at large test-time budgets across several agentic benchmarks, spanning cybersecurity, software engineering, mathematics, academic tasks, and healthcare.
We find that fixed-budget evaluations can systematically underestimate frontier agentic capability, especially for newer models. Firstly, the compute an agent can spend while working on a task – ‘test-time compute’ – is a major driver of its observed capability across many benchmarks. Secondly, the compute a task demands rises with how long it would take a skilled human to complete it, so the longest and hardest tasks are the first to be cut off by fixed budgets. Finally, we find that newer models benefit disproportionately from additional compute. As models improve, the gap between a fixed-budget score and higher-budget capability can widen.
These measurement effects have practical consequences. Restricted-budget scores can make model comparisons unequal, lead decision-makers to underestimate agent capabilities, and obscure the true scale of risks. As agents improve, this blind spot will only grow, unless our measurements account for capability curves.
What we did
Test-time compute can improve performance in two distinct ways. Tokens can be used for different kinds of work: executing task steps or supporting reasoning, planning, and checking solutions. The same compute can also be allocated serially, in one long trajectory that lets the agent explore and fix mistakes, or in parallel, across several shorter attempts to increase the chance that one attempt succeeds (Fig. 1).
Figure 1. How test-time compute shapes performance. A given compute budget can be spent on one long, deep, serial attempt (top) or spread across several shorter, independent attempts that are then aggregated for scoring (bottom). Serial allocation gives the agent headroom for extended work loops, while parallel allocation raises the chance of at least one successful run. Moving the budget cut-off shows how these choices change measured performance.
Rather than scoring each model once at a fixed budget, we swept the token budget from low to high and measured how performance changed. As the budget grew, we tracked four quantities: overall success, reliability, efficiency, and the hardest tasks a model could reach.
We also analysed results at the level of individual tasks, not just whole-benchmark scores. Comparing successive model generations on the same tasks shows how capability curves shift as agents improve.
Our findings
Model capability is not a single score but a curve over test-time compute.
An AI agent’s performance across a set of tasks is best understood as a capability curve, which traces how its score changes as the compute budget grows (Fig. 2). If the curve is still rising when the evaluation stops, the reported score is a lower bound, not the ceiling of the model’s capability.
Figure 2. Each curve illustrates how measured capability changes as test-time compute increases. Raising the budget from Low to High unlocks harder tasks and widens the gap between weaker and stronger models. The greyed-out region is capability that stays hidden when the budget stops the agent too soon. Data are illustrative only.
Across AISI's cybersecurity suite of narrow cyber tasks, we found that a model’s success rate rose steadily with the per-task compute budget (Fig. 3). Around 8% of tasks were only solved once the budget reached 10M+ tokens, some requiring up to 50M tokens. At smaller budgets, those successes would have been invisible. The latest models reached even higher scores at budgets of 100M+.
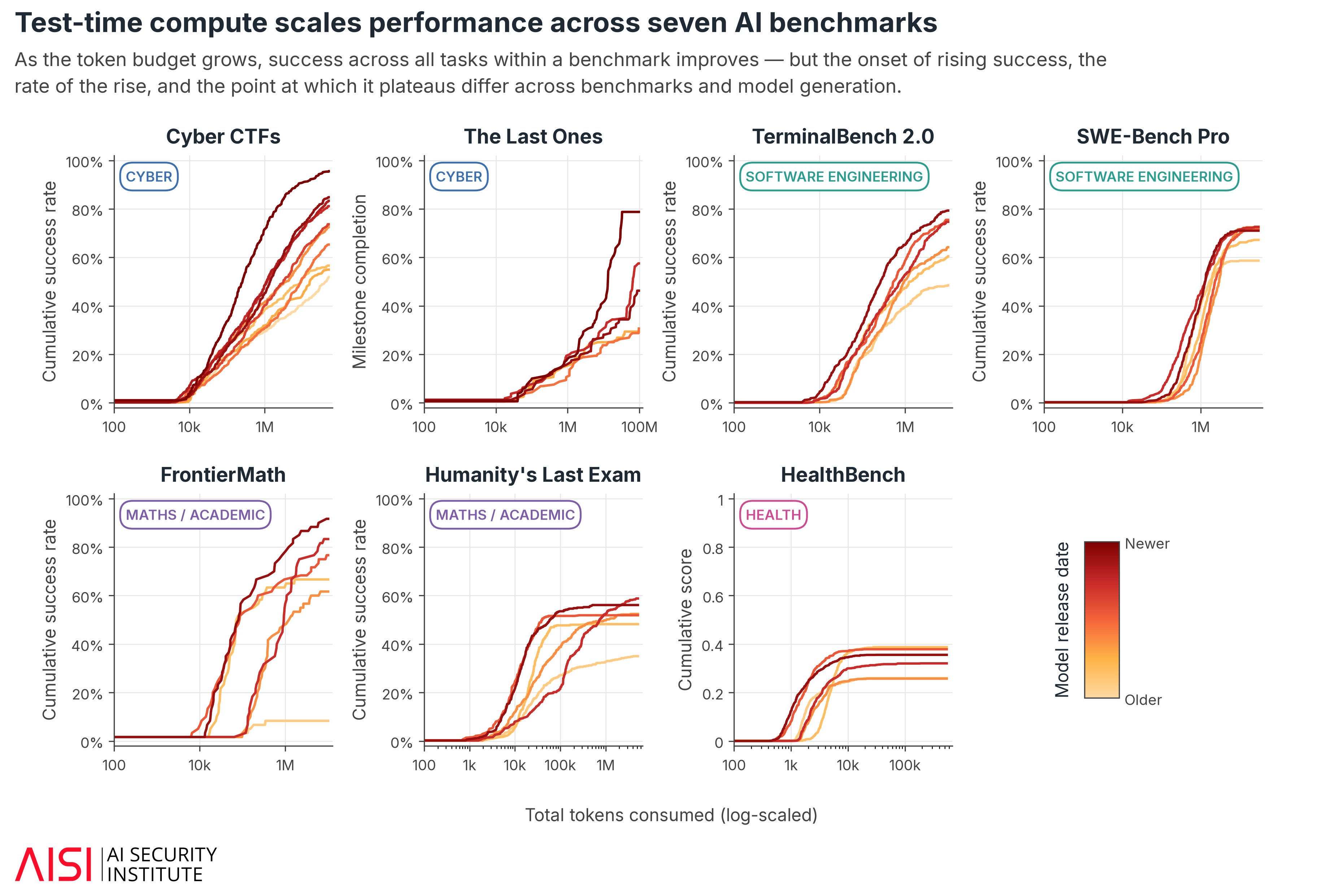
The same pattern holds on public benchmarks. Increasing total token budgets from 1M to 10M raised performance by ~25% on software engineering tasks (TerminalBench 2.0, SWE-Bench Pro) and by ~22% on maths and academic tasks (Humanity’s Last Exam, up to 5M tokens). On TerminalBench, performance keeps improving even after we raise the token budget to 10× what public evaluations typically report.1
The longer a task takes a human, the more compute an agent needs.
Across AISI's cybersecurity tasks and METR's software engineering tasks (Fig. 4), we find that the compute an agent needs to solve a task scales in proportion to how long the task would take a skilled human.2 The pattern holds even for the cheapest successful run for each task, which suggests the floor is set by the work the task requires, not just by inefficient use of compute. This helps explain why benchmark curves can keep rising smoothly as the budget increases: each larger budget reaches another slice of tasks with higher compute requirements.
We have so far tested this only in cyber and software-engineering tasks; the variation around the trend is significant, and human time is an imperfect proxy for task difficulty. As models improve, or in domains where work can be compressed more easily, this floor may move. But for today’s agents in these domains, human task horizon is a useful predictor of the compute needed to observe success on a task.
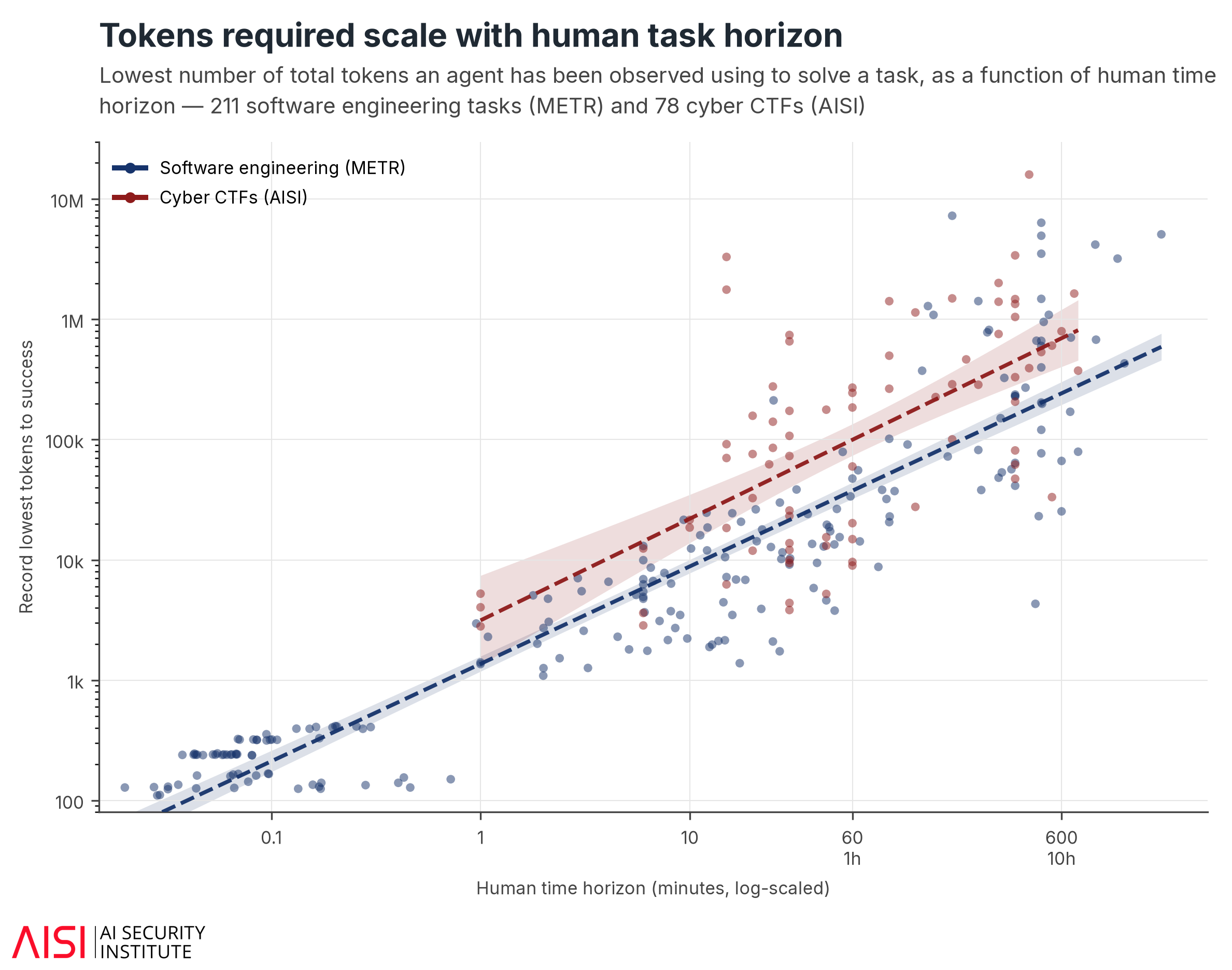
Because the budget a task demands grows with its length, a fixed evaluation budget runs out of tokens on the longest tasks first, while shorter ones still get a full attempt. A capped budget can therefore understate how long a task a model can solve: the tasks it cuts off are systematically the longest, so a failure may mean the run was under-budgeted, not that the agent lacked the capability. For example, AISI’s cyber range ‘The Last Ones’ is estimated to take a human expert roughly 20 hours to complete. No model we tested could complete it until it was given a compute budget of at least 30M tokens.
Higher budgets reveal larger current capabilities and faster frontier progress.
We found that newer models turn additional test-time compute into larger gains than older models (Fig. 5). This means the capability curve does not just move upward, but changes shape, especially on harder tasks.
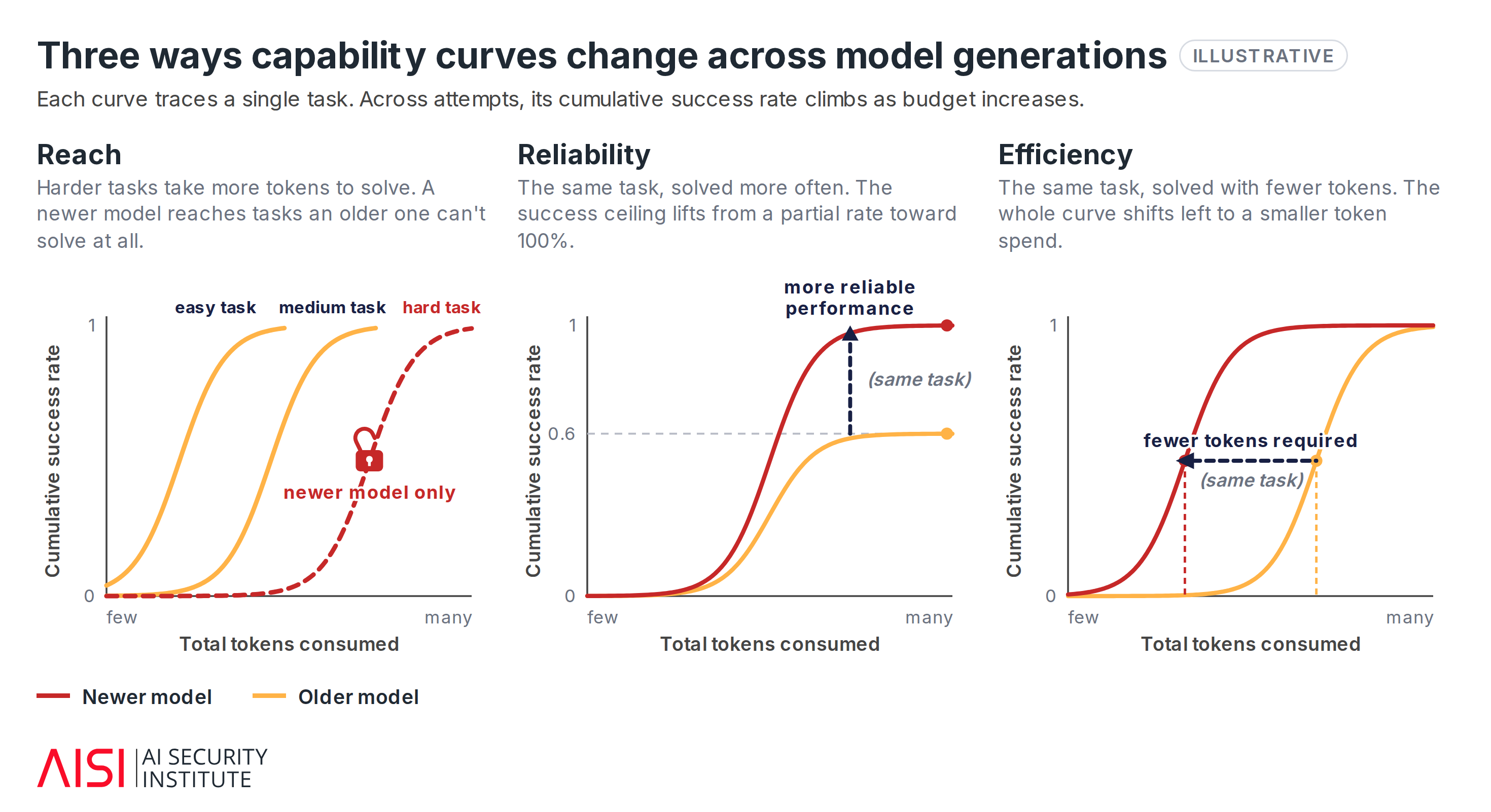
These gains show up along three axes. Newer models solve harder tasks (reach), succeed more consistently on them (reliability), and solve some tasks with fewer tokens (efficiency).3
We often track frontier progress by estimating how quickly models’ time horizon doubles: if a model can complete an 8-hour task today, how long until the next model can manage 16 hours? But a model’s estimated time horizon – and the rate at which this doubles as newer models are released – depends on compute budget.
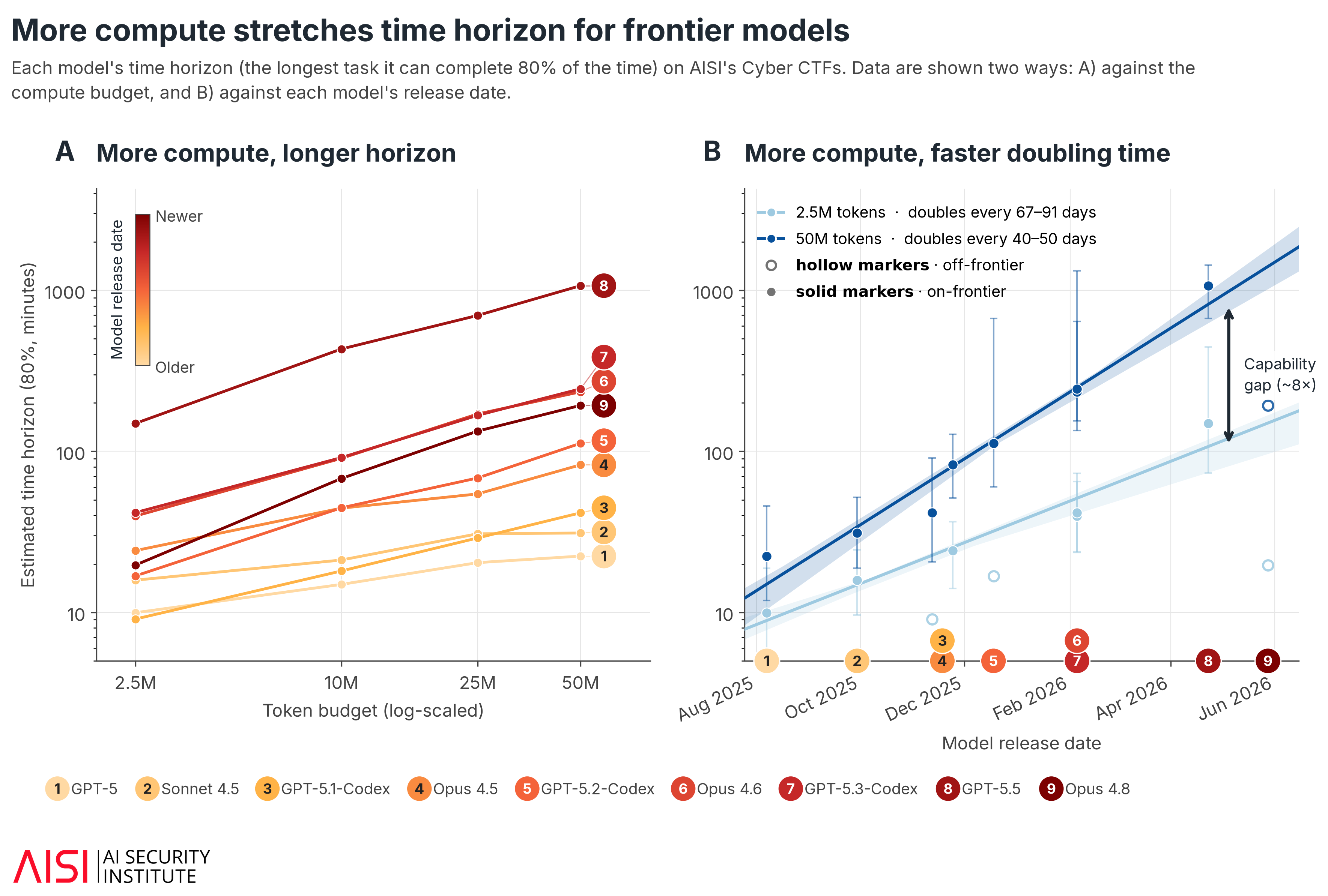
We use this 80% time horizon to ask how quickly cyber capabilities are moving. In previous research, we estimated that frontier model time horizons on AISI’s cyber CTF suite have doubled every 4.7 months since late 2024, measured with fixed budgets at 2.5M tokens per task. We noted that this budget cap could understate what models would achieve with larger compute budgets.
For models released over the past year, the fitted frontier trend is ~60% steeper when horizons are estimated at 50M tokens rather than 2.5M tokens per task (Fig. 6B)4. In other words, the estimated doubling rate is partly a consequence of the compute budget used in the evaluation, not a fixed property of frontier cyber progress.
Figure 6A shows the same effect at the model level. The gap between newer and older models also widens the more compute they are given: one recent frontier model's horizon rose from around 40 minutes at a 2.5M-token budget to around 4 hours at a 50M-token budget (Fig. 6A). At the current frontier, raising the budget from 2.5M to 50M tokens increases the estimated horizon from (roughly) 2 hours to 14 hours (Fig. 6B).
Other research supports these findings. On Epoch’s MirrorCode, where models are asked to rebuild existing software programs from scratch, a recent model used up to 1 billion tokens to make progress that previous models could not, and which would have taken a human engineer weeks of work.
Discussion
Agent capability cannot be interpreted without the compute budget used to estimate it. The budget changes measured performance, sets which task horizons an evaluation can reach, and shapes how fast the frontier appears to move. Evaluations should report capability curves, especially when performance may still be rising.
This matters for decisions about deployment, economic value, and risk: a score measured at too small a budget can make a model look less capable than it would be with more compute in realistic use.
Knowing where capability plateaus is crucial. Importantly, as cost per token falls, higher test-time budgets become increasingly accessible, capabilities that at one time could be prohibitively expensive may become cheaper and more accessible over time.
None of this requires dramatic claims about where AI is heading. It is a question of good measurement: if we keep treating capability as a fixed score rather than a curve over compute, we will keep being surprised by what these systems can do when more is spent on them. For the developers, evaluators, and policymakers who depend on these results, building test-time compute into how capability is measured and reported is the difference between a number that informs a decision and one that quietly misleads it.
Our findings raise three open questions:
- Where does more compute reliably buy more capability, and why? Gains appear strongest where agents can check their work and recover from mistakes, such as code, cyber, and maths. They may be weaker where feedback is absent, delayed, or noisy.
- Can high-budget performance be estimated from cheaper runs? This matters because the most informative evaluations may be expensive.
- How broadly does human task time predict the compute a model needs? The relationship appears in cyber and software-engineering tasks, but it may differ across domains and may change as models become more token-efficient.
Looking Forward
These findings are already shaping AISI’s evaluations:
- We evaluate frontier models across multiple budgets, including very large budgets for the hardest tasks.
- We report reliability and reach against budget, so that a genuinely low-capability model can be distinguished from an under-resourced evaluation.
- We are working to define 'minimum informative budgets', by checking whether a model's reach has stopped rising with more compute.
- We are developing methods to forecast high-budget performance from cheaper runs.
- We are sharing this work with international partners to support robust evaluation and reporting practices for increasingly capable AI agents, as leading providers are now doing.
For more insight on the results of our evaluations, read the full technical papers: on test-time scaling across benchmarks and decomposing test-time scaling curves (forthcoming).
- Compute does not help everywhere: on HealthBench (Fig. 3), every model plateaued within its usual budget. More compute helps most where an agent can check its own work e.g. running code, testing an exploit, and little where feedback is weak or absent.
- The relationship is a power law: across both suites the relationship has a fitted exponent of roughly 0.7–1.0. A task a person could finish in a minute costs an agent thousands of tokens, an hour-long task costs millions, and week-long work runs into billions of tokens. (Work forthcoming.)
- But progress is uneven beneath these averages: on a meaningful minority of tasks: roughly 10–30% depending on the suite, and newer models actually do worse than their predecessors. (Work forthcoming.)
