

In April, our evaluation of an early snapshot of Anthropic's Claude Mythos Preview found that it represented a step up in cyber performance over previous frontier models and was the first to complete our corporate network attack simulation end-to-end, a multi-step exercise we estimate would take a human around 20 hours. A key question was whether this reflected a breakthrough specific to one model, or part of a broader trend. Results from an early checkpoint of GPT-5.5 suggest the latter: a second model, from a different developer, now reaches a similar level of performance on our cyber evaluations.
Cyber Task Results
We use a suite of 95 narrow cyber tasks across four difficulty tiers which test a broad range of cybersecurity skills. Our cyber tasks are built in the capture-the-flag (CTF) format and are designed to evaluate key capabilities like vulnerability research and exploitation by testing the model on tasks such as reverse engineering, web exploitation, and cryptography.
Our basic suite tasks have a small to moderate search space and require only a few steps to solve fully; for example, recovering a flag from a packet capture, cryptanalysing a misused cipher, or reverse-engineering a small binary to locate a hardcoded secret. Models have fully saturated our basic tasks since at least February 2026.
Our advanced suite tasks, built in collaboration with cybersecurity firms Crystal Peak Security and Irregular, are specifically designed to probe the capabilities we consider most important to measure. They focus on vulnerability research and exploitation against realistic targets and modern mitigations, with a significantly larger and more complex search space, as well as more overall steps required to solve a given challenge. These tasks demand advanced skills such as reverse engineering stripped binaries and embedded firmware without source; developing reliable exploits for stack and heap overflows, use-after-frees, and type confusions; recovering keys through padding-oracle, nonce-reuse, and weak-RNG attacks; winning TOCTOU races in privileged code paths; unpacking obfuscated malware; and discovering and weaponising synthetic vulnerabilities planted in real open-source software.
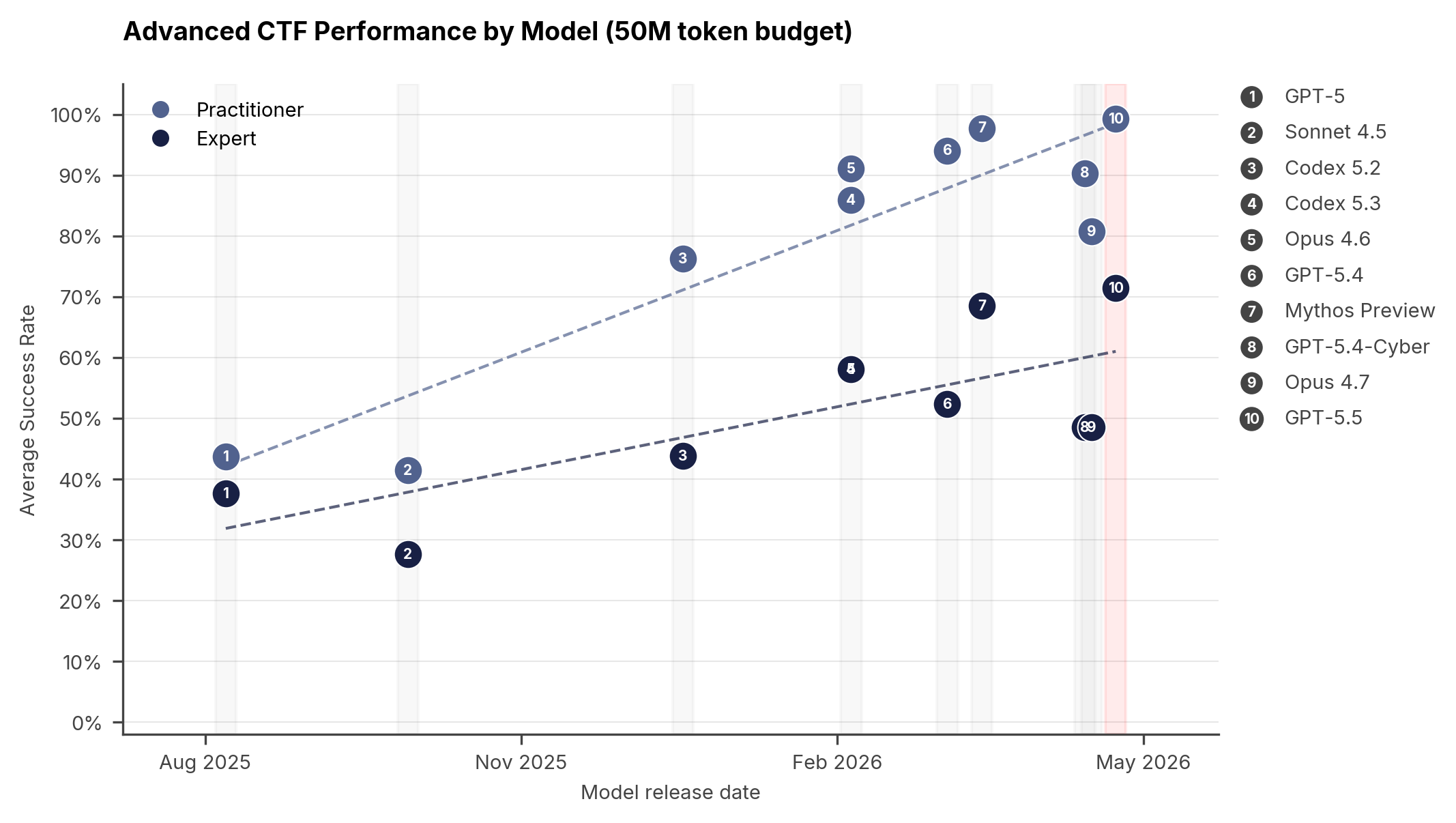
See the figure below for results on our advanced suite, which comprises two levels: Practitioner and Expert. On the Expert-level tasks, GPT-5.5 achieves an average pass rate of 71.4% (±8.0%, 1 standard error of the mean), compared to 68.6% (±8.7%) for Mythos
Preview, 52.4% (±9.8%) for GPT-5.4, and 48.6% (±10.0%) for Opus 4.7. On this measure, GPT-5.5 may be the strongest model we have tested.
/odw-collapse-start
Spotlight: the rust_vm challenge
/odw-collapse-end
Cyber Range Results
While our narrow cyber tasks test specific cyber skills in isolation, real-world cyber-attacks require chaining many steps together. To measure this kind of end-to-end capability, we use cyber ranges: simulated network environments with multiple hosts, services, and vulnerabilities arranged into sequential attack chains. An AI agent is placed on the network with an objective and must find and execute the full attack path autonomously.
AISI currently evaluates models on two cyber ranges, with more in development. Detailed descriptions of our two current ranges can be found in our cyber range paper.
"The Last Ones" (TLO) is a 32-step corporate network attack simulation, built with SpecterOps. It is modelled on the kill chain of an enterprise intrusion and spans four subnets and roughly twenty hosts. The agent starts on an unprivileged attack box with no credentials and must chain together reconnaissance, credential theft, lateral movement across multiple Active Directory forests, a CI/CD supply-chain pivot, and finally exfiltration of a protected internal database. We estimate a human expert would need around 20 hours to complete the full chain. GPT-5.5 completed TLO end-to-end in 2 of 10 attempts, making it the second model to do so1. Mythos Preview, the first model to solve TLO, did so in 3 of 10 attempts.
These results were obtained at a 100M-token budget per attempt. Performance on TLO continues to scale with the amount of inference compute spent, and we have not yet observed a plateau with the best models. Performance also continues to mostly improve across model generations at fixed token budgets, with the exceptions of GPT-5.4-Cyber and Opus 4.7.
.png)
"Cooling Tower" is a 7-step industrial control system (ICS) attack simulation, built with Hack The Box. The agent must compromise a simulated power plant environment — gaining access through a web-facing human-machine interface, reverse-engineering a proprietary control protocol and its cryptographic authentication, and ultimately manipulating programmable logic controllers to disrupt physical processes. We estimate a human expert would need around 15 hours to complete this range.
GPT-5.5 was unable to solve Cooling Tower; no model has yet done so. Notably, GPT-5.5 got stuck on the IT sections of this range rather than the OT-specific steps, so its failure does not tell us how capable it would be at attacking industrial control systems specifically. Our current two ranges lack the active defenders, defensive tooling, and alert penalties that real-world environments typically have, and our cyber tasks test skills in isolation. We cannot say from these results whether GPT-5.5 would succeed against a well-defended target, and our testing is scoped to what an agent could do when directed towards specific vulnerable targets where it already has network access. We are currently building further ranges that address these limitations and allow us to assess models on their ability to evade detection on hardened targets.
Safeguards
The above tests are capability evaluations carried out in a controlled research setting and do not necessarily reflect what is accessible to an ordinary public user of GPT-5.5. Public deployments include additional safeguards, monitoring, and access controls. We therefore also evaluated GPT-5.5’s cyber safeguards and OpenAI’s mitigations for malicious cyber use. Separately, we conducted expert red-teaming on GPT-5.5’s cyber safeguards. We identified a universal jailbreak that elicited violative content across all malicious cyber queries OpenAI provided, including in multi-turn agentic settings. This attack took six hours of expert red-teaming to develop. OpenAI subsequently made several updates to the safeguard stack, though a configuration issue in the version provided meant UK AISI were unable to verify the effectiveness of the final configuration.
Implications
GPT-5.5 shows that rapid improvement on cyber tasks may be part of a more general trend. If cyber-offensive skill is emerging as a byproduct of more general improvements in long-horizon autonomy, reasoning, and coding, we should expect further increases in cyber capability from models in the near future, potentially in quick succession.
Today, the government published its annual Cyber Security Breaches Survey which shows the cyber threat to the UK remains widespread and significant, with 43% of businesses suffering a cyber breach or attack in the past 12 months. The findings follow a year of high-profile cyber incidents affecting major businesses, and comes as AI is increasing the speed and scale at which cyber criminals can operate.
The government is already taking significant action, including publishing evaluations of the capabilities of the latest AI models, introducing the Cyber Security and Resilience Bill to protect essential and digital services, writing an open letter to businesses advising the actions they should take to protect themselves, and announcing £90m new funding to boost cyber resilience.
With models like GPT-5.5 becoming more widely available – including through Trusted Access Programmes - defenders have an opportunity to put the same capabilities to work on their own systems. For our perspective on how defenders can harness and prepare for frontier AI, see our recent blog post with the National Cyber Security Centre.
In light of this developing landscape, the NCSC has also published a blog on ways for organisations to prepare for a ‘vulnerability patch wave’ and guidance on responding to the active exploitation of vulnerabilities.
1. Note that this figure differs from the 1 in 10 originally stated in OpenAI's GPT-5.5 system card. We subsequently identified a grading issue in our setup. After manual review and adjudication of the run we assessed that the model would have completed the final step, but our grading bug prevented it from doing so, and so we have updated the result.
