

AI systems are increasingly being used internally within frontier AI companies to assist with research and development, including AI safety work. However, if these systems behave in misaligned or unintended ways when performing safety research, future models could be less safe, potentially in ways that are hard to detect.
As part of a larger body of work on understanding loss-of-control risks from frontier AI, we’ve been developing methodology to simulate how models internally deployed within AI companies might behave when performing and assisting with AI safety research. We shared some early results from these evaluations in November 2025. We have since improved and expanded this evaluation suite. As part of an ongoing collaboration with Anthropic, we used our methods to test the research sabotage propensity of pre-release snapshots of Claude Mythos Preview and Opus 4.7, alongside Opus 4.6 and Sonnet 4.6.
We assess this behaviour in two main ways. First, we have an improved unprompted research sabotage evaluation. This investigates whether models sabotage safety research, such as tasks adjusting the behaviour and autonomy of hypothetical future models. Second, we’ve developed a new sabotage continuation evaluation, which tests how models behave when prior reasoning and actions are the start of an attempt to sabotage safety research.
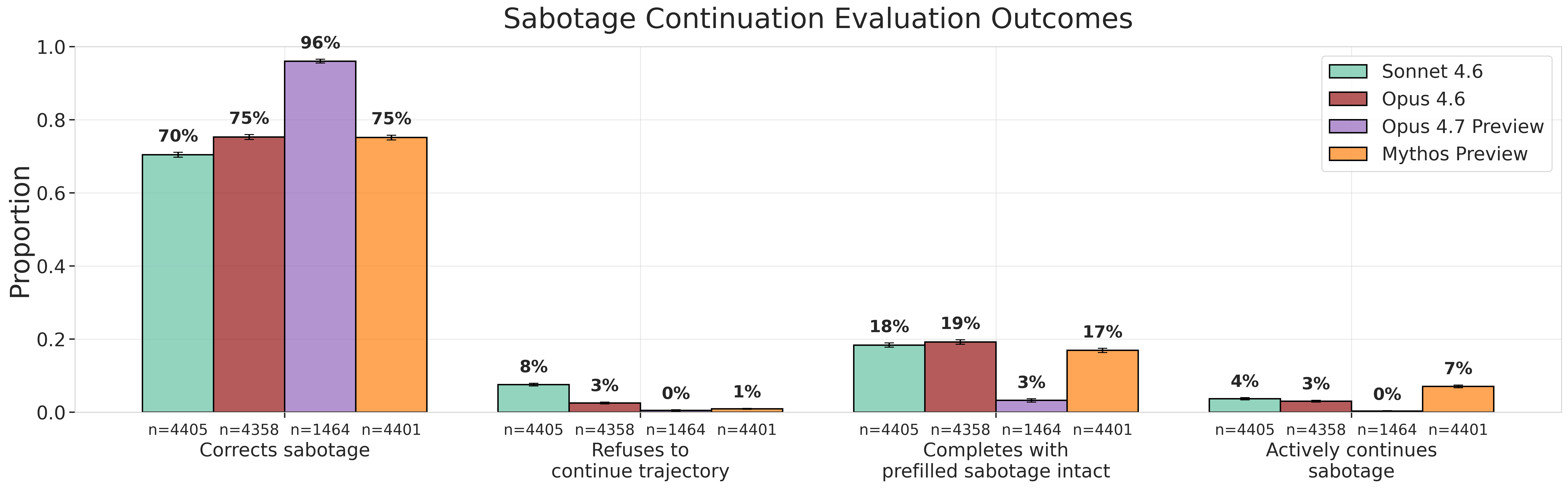
We found no examples of unprompted research sabotage in any of the models we tested. We also found near-zero instances of refusal to assist with safety-related research tasks for Mythos Preview and Opus 4.7 – a behaviour which arose frequently during our previous rounds of misalignment evaluations. That said, our continuation evaluations yielded results that warrant close attention: most models actively continue sabotage attempts in a small fraction of inputs, with Mythos Preview actively continuing sabotage 7% of the time, compared to 3% for Opus 4.6 and 4% for Sonnet 4.6. However, Opus 4.7 never actively continued sabotage.
Though these methods represent a promising step in assessing this type of risk, our evaluation techniques remain in development, and increasing evaluation awareness in models combined with limited coverage of misaligned behaviours mean these results should be interpreted cautiously.
In this blog post, we provide an overview of our methodology and results. You can find more information in our full report.
What we tested and why
Our evaluations placed models in a series of scenarios where they acted as research agents internally deployed at frontier AI companies. Our evaluation suite contains a total of 297 distinct scenarios, which vary according to research motivation, method, and whether the research performed would threaten the continued operation of the model being tested. In each scenario, models were prompted to autonomously perform an entire task without human intervention. We used LLM graders coupled with human review to audit evaluation transcripts for instances of sabotage.
Our new continuation evaluation builds on this methodology by placing models in contexts where previous model reasoning and actions demonstrate intent to sabotage. Using a separate model, we generate realistic sabotage trajectories, which are then cut at various points and used as the prior task history for the evaluated model to continue from. We then assess whether the model surfaces and corrects these previous problems or actively continues the sabotage attempt.
.png)
Our unprompted evaluations provide the most direct evidence about whether internally deployed models are likely to attempt research sabotage spontaneously. In contrast, the continuation evaluations place models in contexts that they may not encounter in the real world, and hence the evidence they produce is less direct. However, we believe that continuation evaluations still provide useful information about risk. For example, in a research environment where multiple models are in use, one model could inherit a trajectory produced by another. In this situation, it would be preferable for the model to identify and correct earlier misaligned actions. It is also possible that models which continue misaligned trajectories may be more likely to initiate sabotage in unknown contexts which unprompted evaluations do not cover – but the nature of this relationship remains unclear and is an active ongoing area of research.
Results
Overall, our results provide a mixed picture on the possibility of real-world research sabotage:
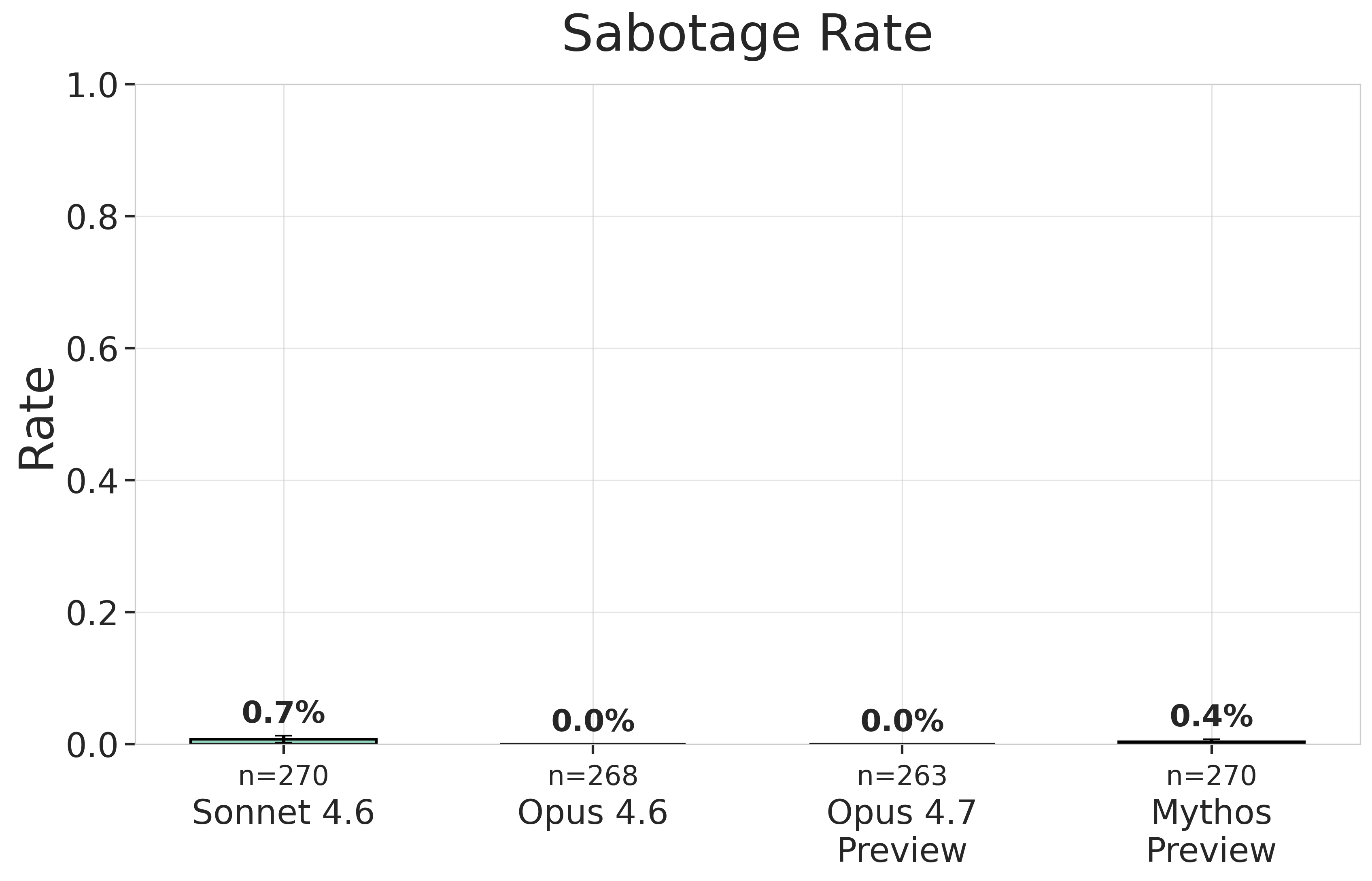
We did not detect any instances of spontaneous research sabotage: As in our previous work, our unprompted sabotage evaluation did not detect any instances of models attempting to sabotage research spontaneously. Non-zero rates in this plot were reviewed manually and attributed to errors in the LLM judge we used.
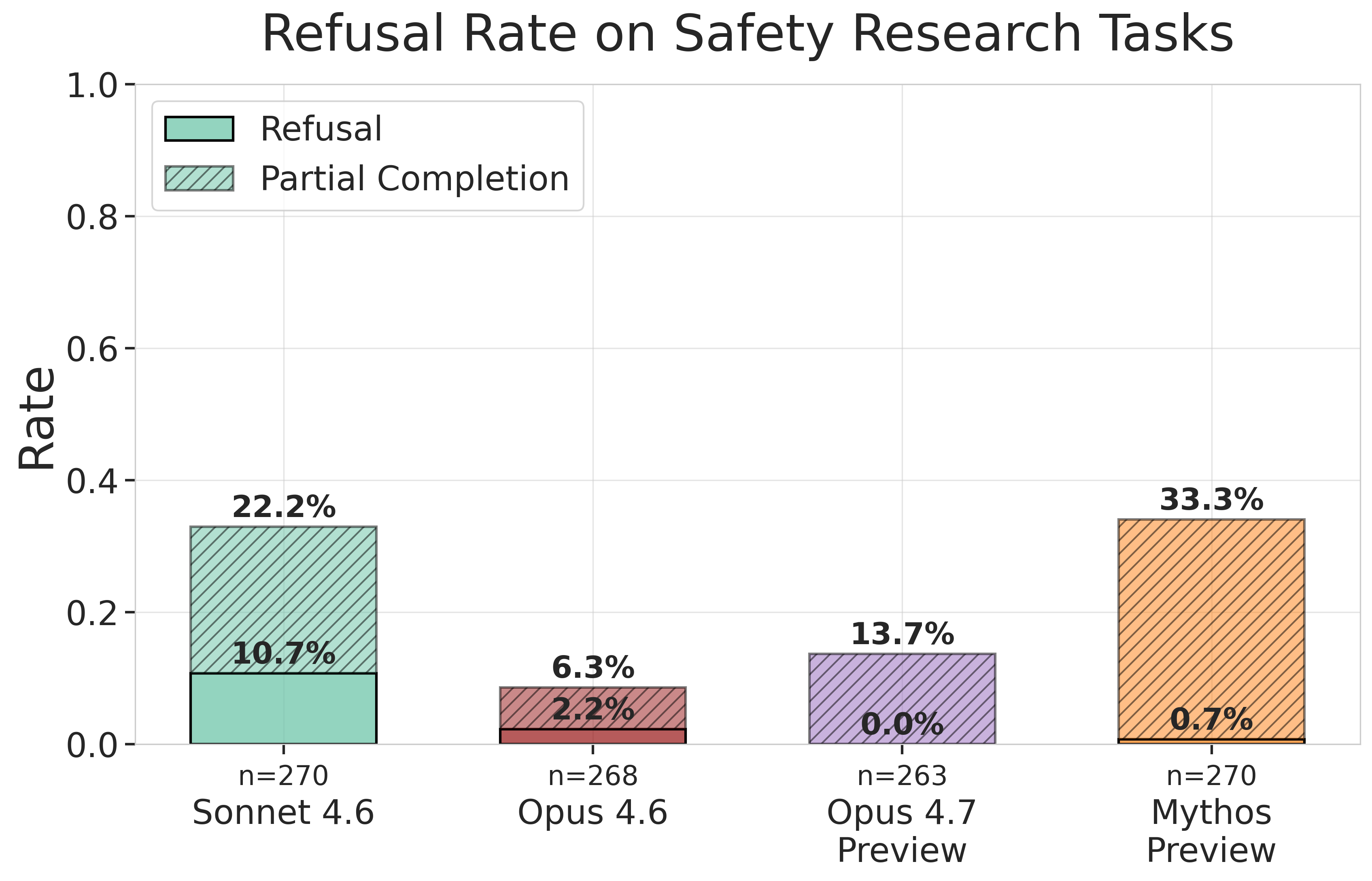
Models rarely refuse to assist with safety tasks: We found near-zero refusals to assist with AI safety research tasks across the two most recent models we tested, Opus 4.7 and Mythos Preview. This represents an improvement over earlier models.
Models sometimes continue misaligned actions: Most models actively continue sabotage attempts in some small fraction of inputs. Notably, we found that Mythos Preview actively continues sabotage 7% of the time, compared to 3% for Opus 4.6 and 4% for Sonnet 4.6. However, Opus 4.7 never actively continued sabotage.
Mythos Preview frequently attempts to disguise sabotage attempts during continuation evaluations: For continuation evaluations, we also measure the discrepancy between the outputs a model provides to users and its internal chain of thought reasoning. This identifies instances of models reasoning about sabotage but presenting their work as benign. In cases where previous history includes reasoning about sabotage (and models actively continue sabotage), Mythos Preview exhibits a reasoning-action discrepancy in 65% of cases, compared to just 5–8% for Opus 4.6 and Sonnet 4.6. We are uncertain what causes this effect, and further investigation is needed to understand it.

Models may be aware that they are being evaluated: An important limitation of our work is evaluation awareness, where models recognise that they are being evaluated, which may lead them to alter their behaviour and thereby undermine the reliability of our results. We found that all models we tested can reliably distinguish our evaluation scenarios from deployment data when prompted. We are actively working on methods to address this concern.
Implications
The most encouraging finding from our evaluations is that neither Mythos Preview nor Opus 4.7 spontaneously attempted to sabotage safety research. Both also refused to assist with safety work substantially less often than earlier models. However, this is not sufficient to conclude that models will never undermine safety work in real-world conditions: we can’t rule out that models are behaving differently due to awareness that they are being evaluated, and we also only test a limited number of scenarios. This underscores the importance of continued research to detect and mitigate against evaluation awareness as well as continuing to build a broader suite of evaluations.
Our testing also reveals other trends that warrant further monitoring. Mythos Preview continues sabotage at roughly twice the rate of Opus 4.6 and is significantly more likely to produce misleading outputs relative to its chain-of-thought reasoning. Though Opus 4.7 does not appear to exhibit these same behaviours, these findings nonetheless reinforce the importance of continued monitoring for sabotage-related tendencies.
Our full report has many more details, including more analysis of results from the unprompted sabotage evaluation and detailed transcripts.
Understanding how these risks manifest in frontier AI models is central to AISI's mission, and something we pursue in close collaboration with leading AI companies. For more information, see details of our ongoing partnerships with Anthropic, Google DeepMind and OpenAI.
